Building the Investor Ready MVP: Your Blueprint to Funding

You’re probably in the most awkward stage of startup building.
The product works. Early users don’t hate it. A few even love it. You can demo the flow without apologizing. Then you get into investor conversations and the questions change fast. They stop asking what the product does and start asking whether the technology can survive growth, diligence, hiring transitions, and security scrutiny.
That’s where most founders realize they don’t have an investor ready mvp. They have a functioning product with uncertain technical value.
I’m opinionated on this. Investors rarely care that you shipped fast if the codebase looks like it will collapse the moment they fund growth. A messy MVP doesn’t just create engineering problems later. It lowers confidence now. It tells investors you may need a rebuild, a rescue hire, or a painful slowdown right after the round.
An investor-ready MVP is not a prettier prototype. It’s a product, codebase, infrastructure setup, and documentation layer built to reduce risk. It proves your team can make disciplined technical decisions under pressure. That is exactly what investors are trying to assess.
From Working MVP to Valuable Asset The Mindset Shift
A working MVP solves a user problem. A valuable asset solves a user problem and stands up to scrutiny.
That’s the shift.

What investors are really assessing
When investors look at your MVP, they’re not grading feature count. They’re reading signals:
Decision quality: Did you choose the smallest feature set that proves demand?
Execution discipline: Does the product feel coherent, or stitched together?
Risk awareness: Have you reduced obvious technical, security, and operational landmines?
Scalability posture: Is this a foundation, or a dead-end build?
If your current product requires a long verbal defense to explain why the architecture is temporary, why the auth flow is fragile, or why the analytics are incomplete, you’ve already lost ground.
A prototype says, “we can build.” An investor ready mvp says, “we can build a company.”
The wrong founder instinct
Most founders respond to investor pressure by adding features.
That’s usually the wrong move.
If your product is shaky, another feature only increases the surface area of the problem. You don’t improve valuation by expanding a weak system. You improve valuation by making the system more reliable, more measurable, and more transferable to future hires.
Here’s the practical test I use.
Question | Working MVP | Valuable technical asset |
|---|---|---|
Can users complete the core workflow? | Yes | Yes |
Can a new engineer understand the system quickly? | Maybe | Yes |
Can you explain the architecture in one diagram? | Rarely | Yes |
Can you show how you monitor failures and behavior? | Often no | Yes |
Would an investor fear a rebuild after funding? | Often yes | No |
The founder standard to adopt now
Treat every engineering decision as a valuation decision.
That means:
Cut scope harder than feels comfortable. Narrow scope is not weakness. It’s discipline.
Build only core workflows. The MVP should cover the job users hire it to do.
Instrument behavior from day one. If you can’t measure activation and retention, you can’t defend traction.
Document your technical choices. Investors want to know why the system is built this way, not just that it works.
Eliminate avoidable debt early. Debt is acceptable only when it’s deliberate, tracked, and contained.
What this changes in practice
You stop asking, “Can we launch this?”
You start asking, “Will this survive diligence, team growth, and investor questions without a credibility discount?”
That mindset changes everything. It changes how you scope. It changes who you hire. It changes whether your MVP becomes an advantage or baggage in the fundraise.
Engineering an Audit-Ready Technical Moat
Founders love to say they want a scalable product. Most of them build a fast shed and call it a skyscraper plan.
An investor ready mvp needs a technical moat. Not in the inflated startup sense. I mean a codebase and system design that makes your company easier to scale, easier to diligence, and harder to dismiss.
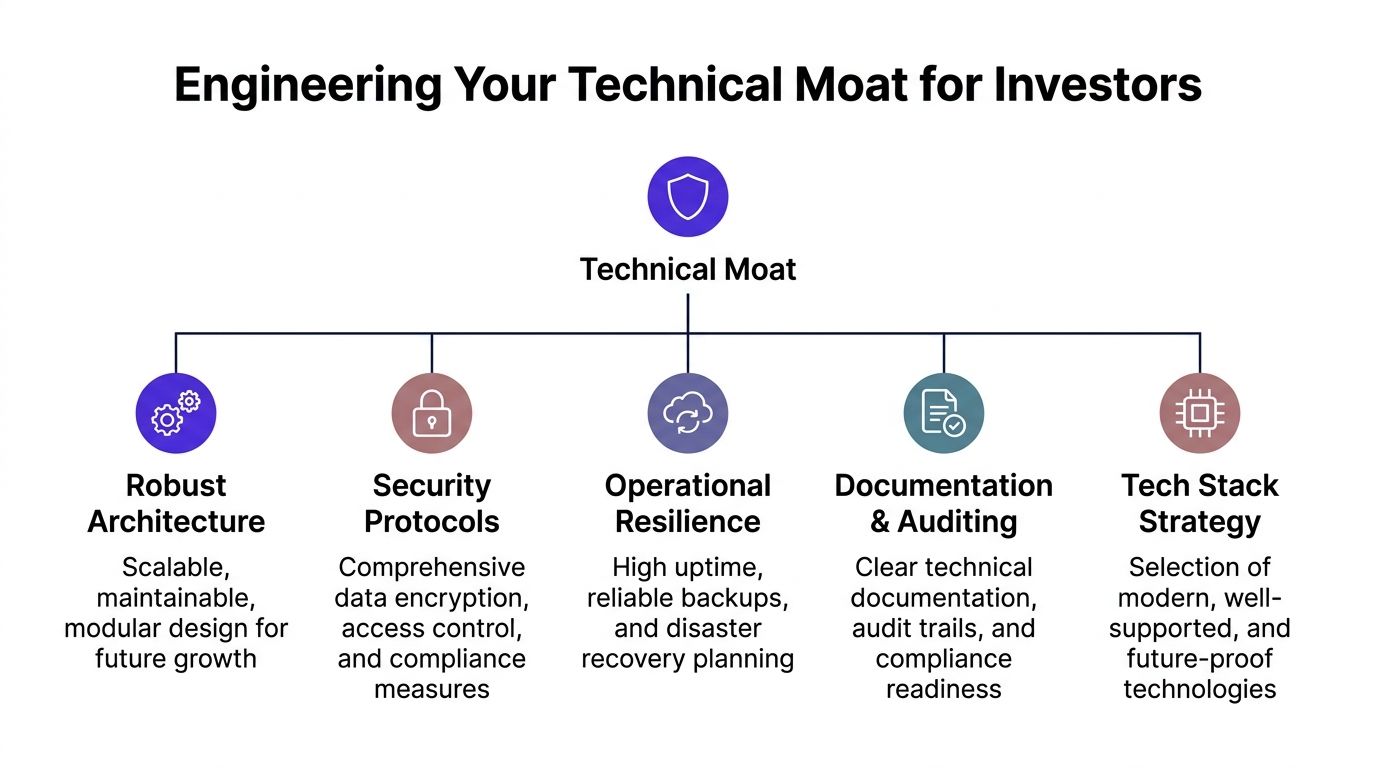
Start with architecture that fits your stage
A lot of early teams overreact to “scale” and build complexity they can’t manage. They reach for microservices, event buses, and distributed workflows before they’ve earned the right.
That’s amateur behavior.
For most early SaaS products, a well-structured monolith is the right call. It’s easier to ship, easier to debug, and easier for future hires to reason about. Investors don’t reward performative architecture. They reward sane architecture.
What matters is whether the system is:
Modular enough that core domains are separated cleanly
Predictable enough that onboarding a new engineer doesn’t require tribal knowledge
Stable enough that one urgent fix doesn’t break unrelated features
Portable enough that you can evolve pieces later without a total rewrite
Production-grade means more than code that runs
I don’t use “production-grade” loosely. For a startup MVP, it means the system behaves like a business asset.
That usually includes:
Version-controlled infrastructure and app code
A defined deployment pipeline
Clear environment separation
Authentication and permission boundaries
Error monitoring and structured logging
Basic test coverage around the core flow
Architectural documentation that another engineer can inherit
Investors don’t inspect every line. They inspect your operating maturity through the artifacts around the code.
CI/CD is not optional
If your team deploys through manual rituals and private Slack knowledge, you’ve built fragility into the company.
Set up CI/CD from day one. GitHub Actions, GitLab CI, or a similar system is enough. The exact tool matters less than the habit. Every pull request should trigger the same checks. Every deployment should follow the same path. Every release should be recoverable.
That gives you three advantages:
Consistency during rapid iteration
Traceability when something breaks
Transferability when the team grows
Those aren’t engineering luxuries. They’re diligence signals.
Practical rule: If a critical release depends on one engineer being awake, your architecture is weaker than you think.
Technical debt should be managed like a liability register
Technical debt isn’t evil. Hidden debt is.
I want founders to stop using “we’ll clean it up later” as a default operating model. That phrase usually means nobody owns the cleanup, nobody understands the risk, and future engineering time is already mortgaged.
A better approach is simple:
Debt type | Accept it when | Reject it when |
|---|---|---|
Temporary UI shortcuts | It speeds validation without harming core trust | It pollutes every key user path |
Internal code duplication | It helps prove a workflow quickly | It makes bug fixes inconsistent |
Simplified infra setup | It reduces launch friction | It blocks safe deployment or monitoring |
Manual admin operations | Volume is low and documented | Revenue or support depends on one founder |
The point is not “no debt.” The point is named debt with an owner and a removal plan.
Build for external scrutiny, not internal comfort
Technical reviews often expose the gap between how founders feel about the product and how others evaluate it. One investor-ready MVP guide points out that startups are often unprepared for technical reviews and notes a gap around diligence-specific benchmarks like maintainability scoring and debt visibility in audit contexts in its discussion of investor-ready MVP technical diligence gaps.
That gap is real. Many teams don’t fail because the product is impossible. They fail because nobody can prove the engineering is controlled.
Use simple diligence artifacts early:
Architecture diagram
Repository map
Deployment workflow
Dependency and service list
Known debt register
Access control summary
Incident response basics
The team structure matters as much as the stack
A sloppy team can ruin a good stack. A disciplined team can make a simple stack look excellent.
You need clear ownership. Someone should own architecture. Someone should own release quality. Someone should own security basics. On a small team, that may be one person wearing multiple hats. Fine. Just make the responsibilities explicit.
Hardening Your MVP for Scale and Security
A founder can talk their way around missing features. They can’t talk their way around an outage, a breach, or a visibly brittle deployment process.
Investors treat operational weakness as a multiplier of all other risk. If the product can’t stay up, can’t protect user data, or can’t deploy safely, every traction number becomes less credible.

What hardening means
Hardening is not enterprise theater. It’s the smallest set of controls that makes your system trustworthy.
For an early-stage product, that usually means:
Access discipline: limit production access, use role separation, remove stale credentials fast
Secrets handling: store keys and credentials in a proper secret manager, not in code or random docs
Transport and data protection: encrypt data in transit and protect sensitive data at rest
Dependency hygiene: keep frameworks and libraries updated on a routine cadence
Backup confidence: know what gets backed up, where, and how recovery works
Logging and alerting: capture errors, auth anomalies, failed jobs, and deployment issues in one place
You don’t need a giant platform team to do this. You need operational seriousness.
The startup security checklist investors expect
I don’t advise founders to boil the ocean. I advise them to eliminate obvious reasons for investor concern.
Use this checklist:
Lock down authentication first. Weak auth destroys trust faster than missing features.
Review authorization paths. Many early products know who a user is but don’t control what they can access.
Protect admin functions. Admin panels are often the least-defended, highest-risk part of the app.
Set up monitoring. Sentry, Datadog, CloudWatch, or similar tools are fine. Silence is not.
Create rollback paths. If a deployment breaks production, your team should know how to revert cleanly.
Separate environments. Staging should not be a weird clone of production held together by luck.
Document incident ownership. If something goes wrong at midnight, who responds first?
Reliability is part of the product. Users experience your infrastructure whether you mention it or not.
What investors like to see in infrastructure
They don’t need your infrastructure to be massive. They need it to be coherent.
A useful benchmark from an MVP measurement guide is that technical specs for investor audits can include multi-region cloud infrastructure on AWS or GCP, SOC2-lite compliance, and zero-downtime deploys via Kubernetes, with the article also claiming an 85% due diligence pass rate and a 30% valuation boost for those stack patterns in its framing of technical specs for investor audits.
You don’t need to copy that stack blindly. But the underlying principle is solid. Investors trust systems that show:
Area | Weak signal | Strong signal |
|---|---|---|
Hosting | One-off setup no one can explain | Cloud setup with clear ownership |
Deployments | Manual pushes | Repeatable deploy process |
Compliance posture | “We’ll handle it later” | Basic policy and access discipline |
Availability | Hope | Monitoring, rollback, backup awareness |
Don’t fake scale. Design for controlled growth
A lot of founders hear “scale” and think they need heavy infrastructure now. That’s wrong.
For an investor ready mvp, use managed services where possible. Use a cloud database you trust. Use object storage. Use managed queues if the workflow calls for them. Use container orchestration only if the team can support it. Avoid custom infrastructure that exists mainly to signal sophistication.
What matters is whether you’ve made choices that can grow without forcing a dangerous rewrite.
Operational readiness is visible
If I were reviewing your startup tomorrow, I’d ask for four things before I asked for advanced architecture details:
How do you deploy?
How do you detect failures?
Who has production access?
How do you recover from mistakes?
If those answers are vague, your product isn’t hardened. It’s exposed.
Proving Traction with Investor-Centric Metrics
A strong investor ready mvp is a measurement system with a product attached.
Founders often show investors screenshots, demos, and anecdotes. That’s not enough. Investors want behavior data. They want proof that users hit the value moment, come back, and convert in ways that justify more capital.
The five metrics that matter first
One of the cleaner benchmark sets for early SaaS fundraising is this: investor-ready MVPs hinge on 5 core pre-seed metrics, including a 20-40% activation rate, 40-60% 30-day retention for B2B SaaS, a 15-30% DAU/MAU ratio, CAC under $500, and early revenue signals such as $0-10K MRR or 5-15% free-to-paid conversion, according to Capwave’s guide to investor-ready pre-seed metrics.
That list is useful because it forces discipline. It keeps founders focused on evidence of value instead of vanity metrics.
What each metric is telling the investor
Use analytics tools like Mixpanel or Amplitude from day one. Not later. Day one.
Here’s the practical reading of the metrics:
Activation rate tells you whether users reach the first meaningful outcome.
30-day retention tells you whether the problem is painful enough to create repeat use.
DAU/MAU ratio tells you how embedded the product is in user behavior.
CAC tells you whether go-to-market is disciplined or wasteful.
MRR or free-to-paid conversion tells you whether users value the product enough to pay.
If one of these is weak, don’t hide it. Explain what you’ve learned and what changed in response. Investors trust teams that can diagnose product truth.
Track user behavior at the event level. “Users are active” is not a metric. “Users completed the core workflow and returned” is.
Vanity metrics to stop leading with
Downloads, signups, page views, and waitlist size can support a narrative. They can’t carry it.
If I see a deck that highlights top-of-funnel volume but can’t answer what users do after signup, I assume the team is avoiding the hard truth.
Use this simple filter:
Metric | Useful alone | Useful with context |
|---|---|---|
Signups | No | Yes |
Page views | No | Rarely |
Activation | Yes | Yes |
Retention | Yes | Yes |
Conversion to paid | Yes | Yes |
Instrument the product around the core value moment
Every startup has a key action that predicts value. For one product it’s creating a project. For another it’s inviting a teammate. For another it’s completing the first workflow.
Your telemetry should answer:
Where do users drop before reaching value?
What behavior predicts retention?
Which segment activates fastest?
Which feature use correlates with conversion?
That’s the story investors want. Not “we built a lot.” They want “we know what creates value, and we can prove it.”
Present traction like an operator
A founder with an investor ready mvp should be able to say, in plain language:
what event defines activation
what retention pattern they’re seeing
what usage cadence matters for their product
where CAC sits today
whether users are starting to pay, upgrade, or expand usage
That level of specificity changes the tone of the conversation. You stop sounding hopeful and start sounding fundable.
Assembling Your Technical Due Diligence Package
Most founders treat diligence like an exam they’ll cram for after the partner meeting.
That’s a mistake.
Diligence starts the first time an investor asks a technical question and watches how precisely you answer. If your architecture only exists in one engineer’s head, if your security posture lives in Slack fragments, and if your roadmap is disconnected from the current system, investors will assume the company is less mature than the pitch suggests.
A proper diligence package fixes that.
The technical annex for your pitch deck
Your main deck should stay clean. Don’t clutter it with deep engineering detail. Add a short technical annex that you can send when interest becomes real.
I’d keep it tight. Usually a couple of slides is enough.
Include:
Stack summary: frontend, backend, database, cloud environment, analytics tools
Architecture snapshot: one diagram that explains system boundaries clearly
Scalability posture: what can already handle growth and what you’ll evolve next
Security posture: auth model, access controls, environment separation, backup policy
Roadmap logic: why the current architecture supports the next product milestones
This isn’t marketing copy. It’s proof that engineering choices were intentional.
The data room structure that saves time
Build a folder structure before investors ask for it. You want speed, not chaos.
A clean diligence data room can look like this:
Folder | What goes inside |
|---|---|
Company architecture | system diagram, service map, environment overview |
Engineering process | branching strategy, code review process, CI/CD summary |
Security and access | access policy, secrets handling overview, incident basics |
Product analytics | dashboards for activation, retention, engagement, revenue signals |
Roadmap and debt | technical roadmap, known constraints, debt register |
Team and ownership | engineering roles, responsibilities, external partner scope |
The point is simple. Don’t make investors hunt.
What belongs in each artifact
A few specifics matter.
In architecture, include a diagram another technical person can read. Name the services. Show the data flow. Show where auth lives. Show third-party dependencies.
In engineering process, include enough to prove repeatability. A screenshot of your CI pipeline is useful. A short note on deployment flow is useful. A vague claim that “we follow best practices” is useless.
In security, document who can access production, how credentials are handled, and how you approach release safety. You don’t need to hand over secrets. You need to prove controls exist.
Investors don’t need every internal document. They need enough evidence to conclude your team is in control.
Link technical diligence to financial diligence
Strong investors won’t separate technical quality from financial quality for long. If your codebase creates future rebuild cost, hiring friction, or operational risk, that becomes a financial issue.
That’s why founders should understand not only technical review, but also how buyers and investors approach financial due diligence. The technical package and the financial package should tell the same story. Capital goes into a company that can execute predictably, not one that needs hidden remediation work right after funding.
Why process discipline changes the outcome
A useful benchmark from Naveck’s investor-focused MVP framework is that a 12-week methodology, with 10-15% of budget reserved for customer discovery and scope limited to 20-30% of full functionality, can eliminate the technical debt that derails 70% of Series A audits, and the same source says fractional CTO oversight can lead to a 90% audit pass rate in this context of rigorous MVP methodology and audit readiness.
That’s why I push founders to build the diligence package while the product is being built. The package is not paperwork. It’s evidence that the company knows what it’s doing.
The Strategic Trade-Offs Timeline, Cost, and Valuation
Founders usually ask the wrong question.
They ask, “What’s the cheapest MVP we can get live?”
The better question is, “What’s the cheapest path to an MVP that won’t damage the next round?”
That’s a different calculation.
A throwaway build may look cheaper in the moment. But if it creates a rebuild before scale, weakens investor confidence, or slows onboarding after the round, it was never cheap. It just deferred the bill.
The realistic cost of an investor ready mvp
If you want something fundable, plan accordingly. One benchmark states that in 2026, building an investor-ready MVP typically takes 8-14 weeks with budgets starting at $55,000, while specialized firms can deliver on a predictable 12-week timeline for $50,000-$150,000, often 60-75% less than comparable US-based equivalents, according to KVY Technology’s write-up on predictable investor-ready MVP timelines and costs.
That range is useful because it filters fantasy from planning. If someone promises a serious investor ready mvp in a tiny budget with no trade-offs, assume you’re buying hidden debt.
Where founders should spend and where they shouldn’t
Spend on the parts that affect trust, speed of iteration, and diligence readiness.
That usually means:
Discovery and scoping
Architecture
Core workflow engineering
Telemetry
Security basics
CI/CD and release process
Documentation
Be stricter on cosmetic breadth. Extra features don’t impress investors if they sit on weak foundations.
The trade-off table founders need
Choice | Short-term benefit | Long-term cost |
|---|---|---|
Ship fast with weak structure | Earlier demo | Lower confidence during diligence |
Skip instrumentation | Faster launch | Weak traction story |
Ignore infra discipline | Lower upfront cost | Higher operational risk |
Build fewer features well | Slower feature list growth | Stronger valuation narrative |
Valuation follows perceived risk
Investors don’t just price upside. They price execution risk.
When your MVP shows controlled architecture, measurable traction, and credible operations, the company looks easier to fund and easier to scale. That changes the negotiation posture. It reduces the fear that fresh capital will disappear into cleanup.
This is also where cloud discipline matters. Founders often overspend on infrastructure early, then struggle to explain margins and operational judgment. If your team needs a practical reference for trimming cloud waste without harming reliability, this piece on AWS Cost Optimization for EC2 Right Sizing is a useful operational read.
Don’t optimize for launch day alone
Optimize for the first investor technical call, the first senior engineering hire, and the first diligence request.
If you’re budgeting the build now, use a tool like Buttercloud’s MVP cost estimator to frame scope against delivery reality. The point isn’t to chase the lowest number. It’s to understand what level of engineering maturity your budget can support.
A founder building an investor ready mvp is not buying code. They’re buying clarity, transferability, and reduced risk.
That is why the right MVP costs more than a prototype and far less than a rebuild.
If you need a technical partner who can help turn an idea into an audit-ready product, Buttercloud works with founders on product discovery, production-grade MVP development, fractional CTO guidance, and startup infrastructure planning. The right time to build an investor ready mvp is before investors expose the gaps, not after.