CI CD DevOps: The Founder's Guide to Building Value

Your product is live. A customer finds a bug. Your engineer says the fix is ready, but deployment has to wait until tonight because nobody wants to touch production during business hours. Then the release slips, a hotfix goes in manually, something else breaks, and the team spends the evening in Slack trying to guess which change caused it.
That isn't a startup scaling problem. It's a systems problem.
Founders often treat ci cd devops as internal engineering hygiene. That's too small a frame. If shipping software is unpredictable, your company is unpredictable. Investors see that. Senior hires see that. Enterprise customers definitely see that. A fragile release process turns every feature into a risk event, and risk lowers valuation faster than almost any roadmap promise can raise it.
Beyond Code A Strategic Introduction to CI CD DevOps
CI/CD means Continuous Integration and Continuous Delivery. DevOps is the operating model around it. In plain English, it means your team stops shipping software like a nervous artisan workshop and starts shipping like a disciplined production system.
A founder doesn't need to obsess over YAML files or build runners. You need to understand the business consequence. Manual delivery creates hidden drag. It slows launches, makes outages more likely, and produces the kind of technical uncertainty that shows up during due diligence.
Why founders should care early
The strongest engineering teams don't wait until scale to automate releases. They build predictable delivery into the product from the start. That's one reason smart founders choose an architecture and delivery model intentionally, instead of defaulting to whatever a freelancer or early hire happens to know. If you're still deciding how your product should be built, this guide to application development models for startups is a useful companion because delivery speed and product architecture are tightly linked.
Practical rule: If deploying your app depends on a specific person being awake, available, and careful, you don't have a software asset yet. You have operational fragility.
CI/CD is about boardroom outcomes
When I mentor founders, I frame ci cd devops in three terms:
Speed: You can move from idea to released feature without long manual handoffs.
Stability: Automated checks catch problems before users do.
Audit-readiness: Your delivery process leaves a trail. That matters when investors or acquirers inspect your stack.
This is why CI/CD belongs in strategy, not just engineering. A company with predictable software delivery can test faster, recover faster, and earn more trust. That trust compounds.
The Business Case From Technical Debt to Technical Moat
Most founders think technical debt is a code quality issue. It isn't. It's a business model issue. If every release requires caution, ceremony, and cleanup, your product can't compound efficiently.
A proper CI/CD pipeline changes that. It turns delivery from a custom craft into a repeatable system. The market is moving that direction fast. The CI/CD tools market is projected to reach $2.27 billion by 2030, and high-performing DevOps teams using CI/CD are 1.4 times more likely to achieve superior reliability and deployment frequency, while delivering software 2.5 times faster, according to Octopus DevOps statistics.
That isn't a tooling trend. That's a capital efficiency signal.
The factory versus the workshop
An investor-ready software company should operate like a high-precision factory. Inputs go in. Quality checks happen automatically. Defects get caught early. Output is consistent.
A weak startup engineering operation behaves like an artisan workshop. Talented people do heroic work, but every release depends on memory, improvisation, and fragile tribal knowledge. That can produce a demo. It rarely produces a durable asset.
Here's the difference in founder terms:
Model | What it feels like | Business consequence |
|---|---|---|
Manual releases | Late-night deploys, mystery bugs, rollback anxiety | Slower iteration and higher operational risk |
CI/CD pipeline | Automated builds, repeatable testing, controlled releases | Faster learning and stronger technical credibility |
Why valuation rises when delivery gets disciplined
Investors don't just fund features. They fund the machine that can keep producing them.
When a team uses CI/CD well, due diligence gets easier because the company can show:
A repeatable release process: The business doesn't rely on a single engineer's memory.
Lower operational exposure: Bugs are more likely to be caught before production.
Faster learning loops: Product experiments reach users quickly, which improves decision-making.
Scalable engineering habits: New hires join a system rather than inheriting chaos.
A codebase becomes valuable when it behaves predictably under pressure, not when it merely works on demo day.
Technical moat beats technical debt
Founders love the word "moat" when discussing product, market, and distribution. They should use it for engineering too.
A technical moat isn't obscure architecture for its own sake. It's disciplined infrastructure that competitors can't easily copy because it reflects operational maturity. Anyone can mock up a prototype. Fewer teams can ship safely, repeatedly, and under scrutiny.
CI/CD DevOps pays off beyond engineering morale. It reduces friction between product ambition and operational reality. You can launch features without turning each release into a negotiation with risk.
That matters most in the awkward stretch between MVP and serious growth. At that point, you don't need more heroics. You need a delivery engine.
Anatomy of an Investor-Ready CI CD Pipeline
A founder doesn't need to build the pipeline personally, but you should know what happens inside it. If your team says, "the pipeline failed," you should know whether that's a minor issue or a warning that your delivery system is immature.
The cleanest way to understand ci cd devops is to follow the life of a code change through four stages.
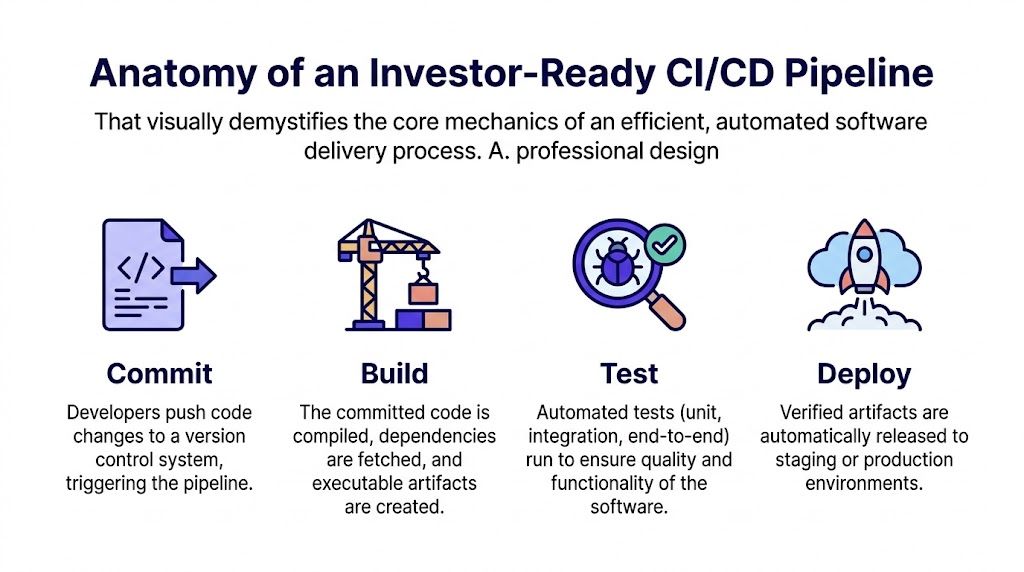
Commit
Everything starts when a developer pushes code to version control, usually GitHub, GitLab, or Bitbucket. That action should trigger the pipeline automatically. If an engineer still has to remember extra manual steps after committing code, your system has already introduced risk.
Commit is where discipline begins. Small, frequent changes are easier to verify than giant batches. They also make failures easier to trace.
Good commit hygiene creates business value because it shortens feedback loops. Problems surface earlier, and product progress doesn't get buried inside week-long branches.
Build
Build is the assembly stage. The system pulls dependencies, compiles code, packages assets, and creates an artifact that can run consistently in another environment.
This matters more than founders realize. Without a reliable build stage, teams often end up with "works on my machine" software. That's not just annoying. It's expensive. It means your product depends on local environments instead of controlled systems.
A healthy build stage should answer one question clearly: can this exact version of the product be reproduced and shipped again?
Test
Testing is your quality gate. This stage can include unit tests, integration tests, UI checks, and security scans. The point isn't to chase perfect coverage. The point is to stop obviously dangerous changes before they reach customers.
The strongest pipelines use metrics, not vibes. Elite CI/CD pipelines are orchestrated around DORA metrics, targeting daily deployments, lead times under one hour, and change failure rates below 15%. Teams that monitor these metrics can achieve 2.5x velocity gains and slash rollback times by 80%, according to BMC's guide to CI/CD metrics.
Deploy
Deploy is the controlled release of a verified build into staging or production. In mature systems, deployment is routine. In immature systems, it's theater.
That difference is huge. If deployment feels dramatic, your business is carrying invisible risk. A proper deployment stage should be observable, reversible, and boring. Boring is good. Boring means your team can release often without fear.
What founders should ask their team
You don't need to ask for pipeline trivia. Ask operational questions that reveal maturity.
What triggers the pipeline automatically? If the answer is vague, automation is shallow.
What fails the build? If nobody can say clearly, your quality gate is weak.
How do we know a release is healthy after deployment? If there isn't a monitoring answer, deployment isn't complete.
How fast can we roll back? If rollback is improvised, the process is fragile.
For a broader outside perspective, this roundup of top 10 CI CD pipeline best practices is useful because it shows how experienced teams standardize delivery without overcomplicating it.
The pipeline is not an engineering side project. It's the assembly line for your product company.
What investor-ready actually looks like
An investor-ready pipeline leaves evidence. It shows who changed what, what tests ran, what deployed, and what happened after release. That traceability matters in diligence because it proves your team can scale responsibly.
A founder should be able to answer these questions with confidence:
Can we ship repeatedly without chaos?
Can we detect failure quickly?
Can we reverse a bad release cleanly?
Can we show process, not just promise?
If the answer is yes, your software operation starts looking like an asset instead of a risk center.
Startup Best Practices for Speed and Reliability
Most startup outages don't happen because the team lacked talent. They happen because the release method was reckless. Manual updates to a live system are the software equivalent of changing an airplane engine mid-flight.
The fix is not "be more careful." The fix is to remove unnecessary risk from the release design.
Use Blue-Green deployments when uptime matters
Blue-Green deployment is one of the clearest examples of mature ci cd devops. You maintain two identical environments. Blue serves users. Green receives the new version. After validation, traffic switches atomically from Blue to Green.
That design is powerful because it separates deployment from release risk. You're not modifying the live environment in place. You're preparing a replacement and switching over only when it's ready.
According to iCertGlobal's CI/CD best practices, Blue-Green deployments can reduce deployment-related outages by up to 90% compared to manual updates. Elite teams using this pattern can achieve deployment frequencies of over 100 times per day with failure rates below 0.1%.
Add feature flags to control exposure
Blue-Green handles infrastructure-level safety. Feature flags handle business-level control.
A feature flag lets your team deploy code without exposing it to everyone immediately. That's useful when you're releasing pricing logic, onboarding changes, or a new AI workflow that hasn't seen broad usage yet.
A practical startup pattern looks like this:
Deploy the code first: The feature exists in production, but users can't access it by default.
Expose it to a small segment: Internal users, beta customers, or a limited region can test it safely.
Increase access gradually: Product and engineering can monitor behavior before wider release.
Not every risk is technical. Sometimes the code works fine and the product decision is wrong. Feature flags let you separate those questions.
Release should be a business decision, not a nerve test for engineering.
Design for rollback before you need it
I see founders obsess over launch. They spend too little time thinking about reversal. That's backwards.
A startup should define rollback as part of the release plan, not as an emergency improvisation. For example:
Release element | Weak approach | Strong approach |
|---|---|---|
App deployment | Update production in place | Switch traffic between prepared environments |
Feature exposure | Release to everyone at once | Gate access with feature flags |
Failure response | Engineers investigate after users complain | Monitoring detects issues and rollback is immediate |
Keep startup reliability simple and sharp
You don't need a giant platform team to work this way. You need operational discipline.
Founders should insist on a few habits:
Small changes beat giant launches: Smaller releases are easier to verify and safer to reverse.
Staging should resemble production: If the environments drift, test results lose credibility.
Monitoring must sit next to deployment: A release without observability is blind.
Post-release checks should be automatic: Smoke tests after deployment catch obvious breakage fast.
A startup doesn't earn trust by promising stability. It earns trust by making stable delivery routine.
Securing Your Pipeline for Investor Due Diligence
A lot of founders treat security as a second-phase concern. They plan to "clean it up later" after product-market fit. That logic collapses the moment a serious investor, enterprise buyer, or regulator starts asking questions.
Security gaps inside your pipeline aren't invisible technical details. They are evidence that the company ships software without control.
The real issue isn't speed versus security
Founders often hear "shift security left" and assume the answer is to scan everything at every step. That sounds disciplined, but done poorly it creates slow builds, frustrated engineers, and ritual compliance that nobody trusts.
The sharper approach is targeted security inside the pipeline. A primary reason startups fail investor audits is unaddressed compliance and security risk within CI/CD pipelines, especially insecure dependencies and weak access controls. Regional requirements such as Saudi Arabia's NCA and PDPL add pressure, and overloading pipelines with generic shift-left scans can double build times, while a more nuanced approach can reduce risks 60% faster for MVPs, according to this analysis of CI/CD pipeline challenges.
That should change how you think about DevSecOps. The goal isn't maximal scanning theater. The goal is controlled, auditable delivery.
What belongs inside the pipeline
A secure pipeline should check the things startups commonly miss:
Dependency risk: Open source packages can introduce vulnerabilities or licensing issues.
Secrets exposure: API keys and credentials should never drift into repositories or build logs.
Access control: Only the right people and systems should be able to trigger sensitive actions.
Deployment traceability: Releases should leave a clear audit trail.
These controls don't need to paralyze velocity. They need to be proportional to risk.
Regional compliance changes the standard
Founders building in regulated markets often underestimate local compliance until a customer procurement team or investor counsel gets involved. NCA and PDPL aren't side notes if your product handles sensitive user or business data. They affect how you log changes, manage access, and demonstrate control over your delivery system.
Security that lives in a slide deck won't survive due diligence. Security that lives in the pipeline leaves evidence.
A mature founder asks different questions:
Can we prove who approved production changes?
Can we show that secrets are managed properly?
Can we demonstrate consistent release controls across environments?
Can we explain our security process without hand-waving?
Keep the model practical
Early-stage teams don't need heavyweight process copied from a bank. They need a security model that fits an MVP but doesn't embarrass them later.
A practical approach usually includes:
Automated checks for common issues such as dependency and secret problems.
Manual approval gates for sensitive releases where business or compliance risk is high.
Role-based access around production actions so production isn't casually exposed.
Centralized logs and release records so diligence isn't a forensic exercise.
Many startups fail in this regard. They confuse "we haven't had a breach" with "we have controls." Investors care about controls.
Choosing Your CI CD Tools and Managed Services
Tool selection is where founders often waste time. They compare logos, pricing pages, and feature grids, then choose a stack that's either too flimsy for growth or too complex for the team they have.
The right question isn't "what's the best CI/CD tool?" The right question is "what level of control, complexity, and ownership fits our stage?"
Managed platform versus composable stack
Here's the clean trade-off.
Approach | Best fit | Main advantage | Main risk |
|---|---|---|---|
Managed platform | Early teams that need speed | Faster setup and fewer moving parts | Less flexibility later |
Composable stack | Teams with stronger DevOps ownership | More control and customization | Higher setup and maintenance burden |
A managed path often means using CI/CD close to your code host or platform. That can reduce operational overhead and help an early team move quickly.
A composable path usually means mixing tools like Jenkins, GitHub Actions, CircleCI, ArgoCD, or cloud-native deployment services. This gives you more control over workflows, runners, environments, and policy, but it also requires stronger technical stewardship.
If you're comparing options in the market, this overview of best CI/CD tools is a good starting point because it helps frame the ecosystem before you commit.
Choose based on stage, not ego
Founders get into trouble when they buy infrastructure for the company they hope to become, not the company they are.
For a pre-seed or early MVP team, simplicity usually wins. You want fewer moving parts, strong defaults, and enough automation to avoid release chaos.
For a company approaching Series A, the conversation changes. You may need more explicit environment separation, stronger deployment controls, GitOps workflows, or more opinionated security gates.
What I recommend in practice
I use a simple decision filter with founders:
If the team is small and product speed matters most: Stay close to your repository platform and keep the pipeline understandable.
If compliance is emerging as a real buyer or investor concern: Add controls before complexity spreads.
If multiple services are growing fast: Standardize shared pipeline patterns early so every service doesn't invent its own release logic.
If nobody on the team owns DevOps strategy: Don't pretend tooling will solve that leadership gap.
One option in that last category is a managed partner. For example, Buttercloud's DevOps as a Service includes CI/CD pipeline implementation and infrastructure support for startups that need execution plus technical oversight without building a full internal platform function.
Tooling matters. Governance matters more. A mediocre tool run by a disciplined team will outperform an advanced stack run by guesswork.
Your Rollout Checklist and When to Engage a Partner
The worst way to adopt ci cd devops is in fragments. One engineer adds a workflow here, another writes a deployment script there, and six months later the company has a pile of automation with no operating model behind it.
A better rollout is deliberate. Start simple, but standardize early.
A founder-level rollout checklist
Use this as an executive filter, not a deep implementation spec.
Define the release path: Know how code moves from commit to production, and who approves what.
Standardize one pipeline pattern first: Don't let each service invent its own process.
Set quality gates: Decide what must pass before deployment can happen.
Add release observability: Every deployment should be visible, traceable, and reversible.
Build security into the flow: Access control, dependency checks, and secret handling shouldn't be afterthoughts.
Review pipeline performance regularly: Slow, flaky pipelines become a tax on product development.
When DIY stops being responsible
Some founders hold onto a DIY model too long because the early system "mostly works." That's exactly when risk starts compounding.
Many startups struggle with CI/CD complexity, and pipeline duplication across microservices leads to 50%+ failure rates when scaling MVPs without full-time DevOps hires. The same research notes that 80% of founder queries seek a roadmap tying CI/CD implementation directly to business growth and investor readiness, which is why a fractional CTO can step in with shared, DRY pipelines and strategic oversight, as described by Codefresh on CI/CD best practices.
Those are the signals I watch for:
Clear signs you need outside leadership
Releases depend on one or two people
If deployment knowledge lives in heads instead of systems, you've outgrown improvisation.
Each service has a different pipeline
Variation feels flexible early. Later it turns into maintenance drag and audit pain.
Engineering is shipping, but leadership can't assess risk
If you can't tell whether your release process is disciplined or dangerous, you need stronger oversight.
Fundraising or enterprise sales are approaching
Due diligence exposes process gaps quickly. Waiting until the data room opens is poor timing.
Founder-friendly DevOps doesn't mean doing everything yourself. It means keeping control of the strategy while experts harden the system.
What a fractional CTO should actually do
A real fractional CTO doesn't just recommend tools. They define standards, remove duplication, create release policy, and connect engineering operations to business goals.
That means helping your team answer questions like:
Which parts of the pipeline should be shared across products?
Where do we need manual approval versus full automation?
What controls matter now versus later?
How do we make this system understandable to investors, not just engineers?
If you're feeling delivery pain, funding pressure, or platform complexity, the answer usually isn't "hire faster and hope." It's to install operating discipline before the mess becomes expensive.
If you want a founder-level partner to turn your product delivery into an audit-ready technical asset, Buttercloud works with startups on product engineering, fractional CTO leadership, and CI/CD-driven infrastructure that supports speed, reliability, and due diligence readiness.