Microservices on Kubernetes: Startup Founder's Guide

The most popular advice about microservices on kubernetes is wrong for founders.
You do not get points for adopting the architecture that large platform companies use. You get points for building a company that can ship, retain users, pass diligence, and scale without rewriting the product under pressure.
Kubernetes can help with that. It can also drain runway, slow product delivery, and force premature hiring. For an early-stage startup, that’s not a technical mistake. It’s a capital allocation mistake.
A lot of Kubernetes content skips the hard part. It assumes an enterprise with a mature DevOps function. Even enterprise-focused material admits that microservices and Kubernetes bring significant challenges and additional administrative overhead, while offering little practical ROI guidance for founders choosing between Kubernetes, serverless, and managed containers (EnterpriseDB on microservices and Kubernetes).
My view as a Fractional CTO is simple. Kubernetes is not your starting point. It’s an inflection point. If you adopt it too early, it becomes valuation-destroying complexity. If you adopt it at the right moment, with the right service boundaries and operating discipline, it becomes a technical moat.
Is Kubernetes a Startup Killer or a Technical Moat
Founders ask the wrong question.
They ask, “Should we use Kubernetes?” Instead, consider this question: “At our current stage, does Kubernetes increase enterprise value faster than it increases execution drag?”
That distinction matters. A startup with weak product-market fit does not need elegant distributed systems. It needs customer feedback, release speed, and a codebase that won’t collapse when the first serious customer arrives.
Where founders get trapped
Kubernetes becomes a startup killer when the team uses it to signal sophistication. The stack looks impressive. The business gets slower.
You see the pattern:
Too many services too early. Teams split a small product into multiple deployables before they’ve earned that complexity.
No one owns platform operations. Application engineers inherit cluster work, CI/CD maintenance, and incident response.
Investor-ready gets confused with enterprise cosplay. Genuine diligence focuses on reliability, code quality, security posture, and decision quality. It doesn’t reward unnecessary architectural ceremony.
If you want a useful operating lens for team design, engineering ownership, and delivery accountability, this overview of Microservices Engineering Management is worth reading. Founders underestimate that microservices are as much a management model as a deployment model.
Practical rule: If your architecture decision increases coordination overhead faster than it increases shipping speed, you chose too much architecture.
When it becomes a moat
Kubernetes becomes a moat when it solves a business problem you already have.
That means one or more of these conditions are true:
Your product has distinct workloads with different scaling or runtime needs.
You need stricter isolation between critical paths like auth, payments, ingestion, or tenant-specific processing.
You’re preparing for due diligence and need reproducible environments, clean deployment patterns, and infrastructure discipline.
Your product roadmap includes multiple teams shipping independently without stepping on each other.
In that context, microservices on kubernetes can strengthen valuation because they create an asset with cleaner boundaries, better operational repeatability, and less platform risk later.
The mistake isn’t Kubernetes itself. The mistake is using a growth-stage architecture to compensate for an early-stage business.
The Strategic Tradeoff of Microservices and Kubernetes
Kubernetes is real infrastructure, not startup decoration.
The market validates that. Production adoption of Kubernetes has reached 80%, while 42% of organizations are also consolidating microservices into larger, modular units, which shows the market is moving toward pragmatism rather than hyper-distribution (SoftwareSeni on the CNCF 2025 survey trend).
That single fact should reset how founders think. Mature teams are not abandoning Kubernetes. They are abandoning bad service granularity.
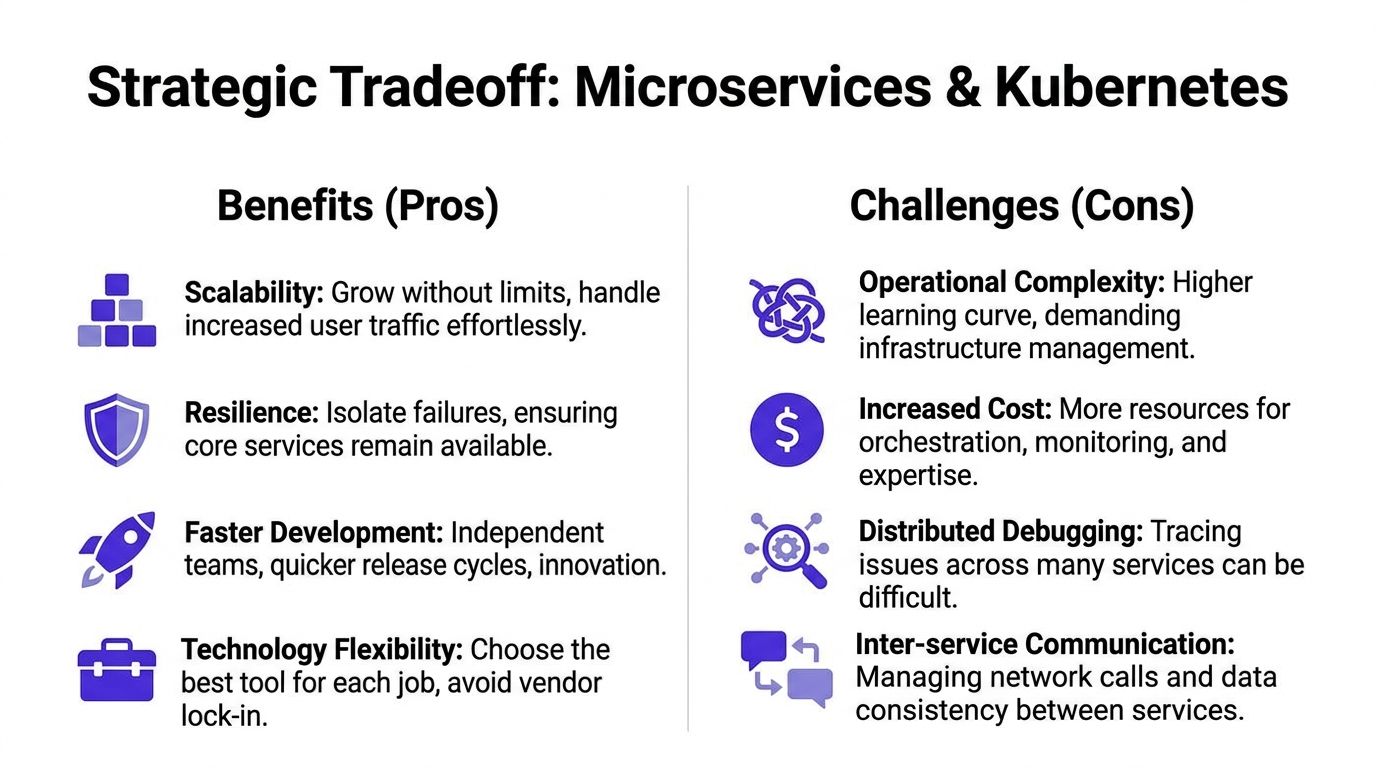
What you gain
Microservices on Kubernetes can provide significant advantage when the product and team are ready.
Strategic gain | What it means for a founder |
|---|---|
Independent deployment | Teams can ship changes in one domain without bundling every release into one risky event. |
Fault isolation | A failure in a non-core workflow is less likely to take down the whole product. |
Workload-specific scaling | You can scale API, worker, and event-processing paths differently instead of over-scaling one big app. |
Technology flexibility | Teams can choose appropriate tools for specific domains when there’s a real reason to do so. |
Operational standardization | Containers, deployment manifests, and cluster policies create repeatable delivery patterns. |
The architecture still matters because it supports products that need to separate billing from analytics, public APIs from internal jobs, or customer-facing traffic from background processing.
What you pay for it
Now the blunt part. You pay a Kubernetes tax.
Not in cloud spend first. In attention.
The cost shows up in areas founders feel:
Hiring pressure. Someone has to own cluster operations, deployment pipelines, secrets, networking, and incident response.
Cognitive overhead. Engineers now think about service boundaries, retries, observability, rollout safety, and inter-service failure modes.
Debugging complexity. A broken user flow can span gateway, app service, queue consumer, and database interactions.
Process rigidity. Teams that haven’t earned platform discipline can end up slower than they were with a well-structured modular monolith.
This is why founders should study the difference between a true distributed system need and architecture theater. If you need a quick strategic refresher, this comparison of monolithic vs microservices architecture is a useful framing tool.
Mature architecture is not more services. It’s better boundaries and fewer unnecessary decisions.
My opinionated recommendation
For most startups, the correct path is not monolith forever and not microservices from day one.
It’s this:
Start with a modular monolith with explicit domain boundaries.
Extract services only where the business earns the separation.
Use Kubernetes when repeatable orchestration, environment consistency, and service isolation create more value than operational drag.
That decision aligns with organizational maturity, not just traffic.
A founder should never say, “We use Kubernetes because we plan to scale.”
A strong founder says, “We adopted Kubernetes because our product has distinct runtime concerns, our release process needed stronger isolation, and our operating model could support it.”
That answer sounds better in diligence because it reflects judgment.
Core Architecture Patterns for an Investor-Ready MVP
An investor-ready MVP does not need a sprawling service graph. It needs a clean architecture that can evolve without a rewrite.
That means keeping the system legible. A founder should be able to point at the core components and explain what each one does, why it exists, and what risk it controls.
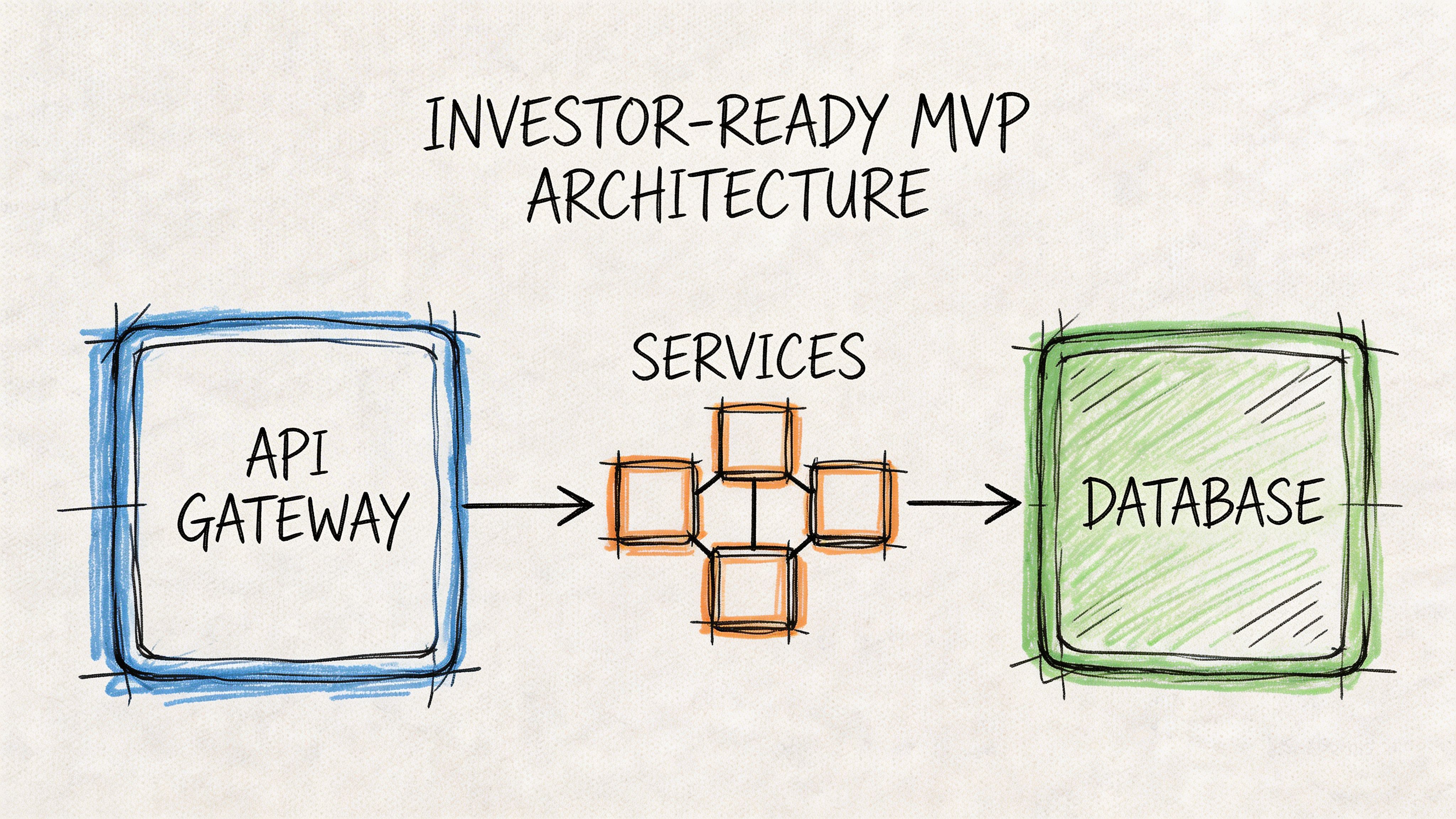
Start with the minimum viable shape
For most startups, the right early architecture on Kubernetes looks like this:
An API gateway at the edge to route requests, centralize auth enforcement, and reduce duplication.
A small number of domain services such as identity, billing, core product logic, and background jobs.
A clear data layer strategy where ownership is explicit and accidental coupling is avoided.
Asynchronous processing for slow tasks like notifications, imports, reporting, or workflow automation.
That’s enough to build a serious product.
It’s also enough to avoid the classic failure mode where a founder inherits ten services, three queues, and no clear explanation of why any of them are separate.
The patterns that matter
API gateway
Think of the API gateway as the front desk for your platform.
It receives traffic, routes it to the right service, and becomes the natural place for authentication checks, rate limiting, and request shaping. Without it, each service starts reimplementing edge concerns, and your architecture gets messy fast.
For a multi-tenant SaaS product, this matters because tenant-aware access rules often need to be enforced consistently. You don’t want every service inventing its own interpretation of identity and access.
Background workers
Not every action should happen in the request path.
If a user uploads a file, requests a report, or triggers onboarding logic, move long-running tasks into workers. That keeps your customer-facing services responsive and easier to scale independently.
This is one of the first separations I recommend because it maps directly to business behavior. User-facing latency and back-office processing are not the same workload.
Sidecar pattern
A sidecar is a helper container that runs next to your main application container in the same pod.
The easiest analogy is a support vehicle traveling with a race car. The race car focuses on speed. The support vehicle handles specialized functions around it.
In practice, sidecars can help with things like:
Traffic management
Telemetry collection
Policy enforcement
Secrets or identity integrations
Founders don’t need to implement every sidecar pattern early. They do need to understand why it exists. It lets your application code stay focused on business logic while operational concerns are handled in a standardized way.
Service mesh
A service mesh is air traffic control for service-to-service communication.
When your system gets large enough, you need a consistent way to manage internal traffic, encryption, retries, and routing policy. A service mesh gives you that control plane without forcing every team to reinvent network behavior in app code.
Don’t introduce a mesh on day one unless you have a strong reason. It’s a later-stage pattern. But once the platform grows, it can make internal communication more governable and more auditable.
If your team still struggles to define clear service boundaries, a service mesh is not your next problem.
Multi-tenant SaaS needs discipline, not complexity
Most founder-led software companies are building some form of multi-tenant SaaS. That changes the architecture conversation.
Your platform needs clean tenant isolation in logic, data access, permissions, and operational visibility. It does not need a separate microservice for every minor feature.
A strong MVP architecture for multi-tenant SaaS favors:
Domain-based service boundaries
Centralized identity and access enforcement
Shared platform capabilities like logging, secrets, and deployment standards
Worker-based separation for expensive background tasks
A clear path to isolate sensitive or high-load domains later
If you’re deciding where language choice, hosting model, and containers fit into that picture, Buttercloud’s guide to a startup tech stack is a useful reference for making those choices in a way that supports later scaling.
What investors want to see
Investors don’t need your architecture to be flashy. They need it to be coherent.
They look for signs that the product can survive growth without a rescue rewrite:
Good signal | Bad signal |
|---|---|
Clear service boundaries | Random service sprawl |
Operational consistency | Each service deployed differently |
Documented dependencies | Tribal knowledge |
Separation of critical paths | Everything runs through one fragile workflow |
Room to evolve | Architecture frozen by early mistakes |
An investor-ready MVP should feel deliberate. Not oversized. Not naive. Deliberate.
Achieving Operational Excellence from Day One
Kubernetes does not reward startups for ambition. It rewards them for discipline.
That is the operational inflection point founders miss. Microservices on Kubernetes can strengthen valuation once your company needs repeatable delivery, clear service ownership, and audit-ready operations. Before that, they can drain runway through tooling sprawl, brittle releases, and cloud waste that nobody owns.
CI CD should remove fear from releases
A startup using Kubernetes needs a release process that works the same way every time.
Founders should demand boring releases because boring releases protect roadmap credibility. If every launch depends on the one engineer who remembers the deployment sequence, you do not have operational maturity. You have key-person risk.
A good pipeline does a few things consistently:
Every service builds the same way
Deployments are automated, not manual rituals
Rollback paths are pre-defined
Configuration changes are versioned
Production changes are observable right away
That consistency matters in due diligence. Investors and acquirers look for systems that can keep shipping as the team grows, not systems held together by Slack messages and memory.
Observability is the difference between a minor incident and a lost week
Kubernetes increases the number of places a failure can hide.
Once requests cross service boundaries, logs alone stop being enough. You need metrics, structured logs, and tracing that answer operational questions fast:
Which service failed?
Was it code, configuration, a dependency, or capacity?
Did the latest release trigger it?
Is the problem isolated to one tenant or affecting everyone?
Treat observability as management infrastructure, not a developer luxury. The cluster is only one layer. The effective operating system of the business includes metrics collection, centralized logging, alerting, and enough request tracing to explain customer-facing failures under pressure.
Cost control has to be designed into the platform
Kubernetes makes overspending easy. Teams add capacity early, forget to rightsize it later, and turn idle infrastructure into a recurring tax on growth.
Set a clear baseline from the start:
Resource requests and limits
Every production workload should declare resource requests and limits.
That gives the scheduler accurate information, reduces noisy-neighbor problems, and forces engineering teams to understand the actual footprint of each service. It also creates a cleaner path to later capacity planning, which matters once board reporting and margin discipline get tighter.
Autoscaling and interruption-tolerant capacity
Use Horizontal Pod Autoscaler for stateless services with variable demand. Use Spot Instances only for workloads that can tolerate interruption. Komodor’s Kubernetes cost optimization guidance notes that rightsizing with requests and limits, scaling with HPA, and placing suitable non-critical workloads on Spot capacity can materially reduce waste and lower infrastructure spend (Komodor on Kubernetes cost optimization).
Be selective. Background jobs, analytics pipelines, and batch processing often fit interruption-tolerant capacity. Core authentication, payments, and customer-facing request paths do not.
Founder lens: If your platform scales faster than your revenue, Kubernetes is hurting valuation, not helping it.
What operational maturity looks like
You do not need a large platform team. You need clear standards and someone accountable for enforcing them.
Operational area | Minimum standard |
|---|---|
Deployments | Automated pipeline with repeatable promotion and rollback |
Capacity | Requests, limits, and autoscaling configured intentionally |
Visibility | Logs, metrics, and tracing tied to releases and incidents |
Cost | Workloads reviewed for rightsizing and interruption tolerance |
Ownership | Every service has a clear responsible team or engineer |
If your team needs help putting those standards in place, DevOps as a Service support for Kubernetes operations is one practical way to get there without hiring a full internal platform function too early.
Operational excellence is not cosmetic. It protects runway, shortens incident time, and turns Kubernetes from founder tax into infrastructure that supports scale.
Building a Secure and Compliant Architecture
A startup does not become audit-ready because it passes a code scan.
It becomes audit-ready because the system is designed to restrict access, segment risk, and surface suspicious behavior before it turns into a breach, a compliance failure, or an ugly investor call.
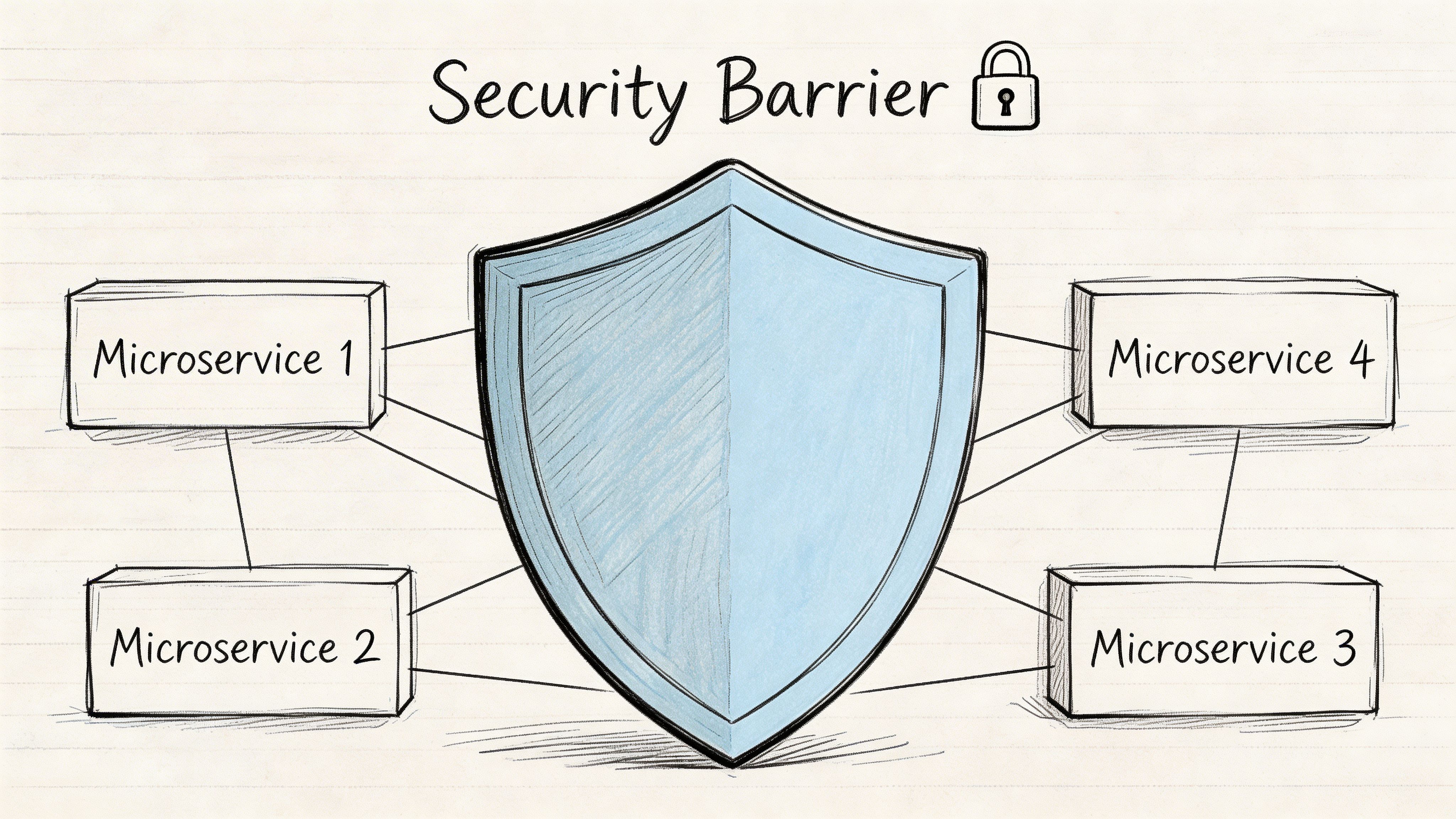
The foundation matters
For microservices on kubernetes, the security baseline starts with boring controls that teams skip when moving fast.
You need:
RBAC so people and workloads only get the permissions they need
Network Policies so services don’t talk to everything by default
Secrets management that avoids credential sprawl in code or config
Image and dependency hygiene so known issues are caught before deployment
Namespace and environment separation to reduce blast radius
None of that is optional if you expect enterprise customers, regulated data, or technical diligence.
A founder should treat these controls as architecture, not compliance paperwork. They shape how damage is contained when something goes wrong.
Static security is not enough
Most startup security guidance stops too early.
It focuses on scanning images, patching dependencies, and checking manifests. Those are necessary. They are not sufficient.
The under-discussed gap is runtime behavior. Kubernetes security-behavior analytics addresses the fact that exploited vulnerabilities show up in what services do after deployment, not just in what they contain, which is why an audit-ready company needs to monitor not just what microservices are, but what they do (Kubernetes on security behavior analysis).
That is the difference between cosmetic security and operational security.
A clean scan does not prove a safe system. It only proves that one layer looked clean at one point in time.
What founders should require
If I’m advising a founder preparing for growth, I push for a minimum viable security architecture with these characteristics:
Least privilege everywhere
Developers, CI pipelines, and workloads should only access what they need.
Overbroad permissions create hidden business risk. A single compromised credential can become a platform-wide event if you don’t constrain privileges early.
East-west traffic control
In a microservices setup, internal traffic matters as much as external traffic.
If every service can call every other service, your cluster becomes flat and fragile. Network segmentation changes that. It forces explicit trust relationships and makes lateral movement harder.
Runtime behavior monitoring
You need some way to identify suspicious process, file, or network behavior in production.
That doesn’t require a giant security team. It requires choosing tools and alerting thresholds that fit your stage, then making runtime visibility part of operations instead of treating it as a future project.
Audit trail discipline
Security incidents and compliance reviews both get worse when nobody can reconstruct what happened.
Your platform should capture deployment history, permission changes, and enough telemetry to explain why a service behaved the way it did. Investors and enterprise buyers both care about that.
Why this affects valuation
Security is framed as a cost center because founders see it after the product exists.
That’s backwards.
A secure architecture reduces downside during customer growth, supports compliance requirements such as NCA and PDPL, and lowers the risk that a serious buyer, enterprise customer, or investor discovers preventable weaknesses during diligence.
In practical terms, strong security architecture does three things:
Protects revenue by reducing outage and breach risk
Speeds enterprise sales because the technical foundation is easier to trust
Improves diligence outcomes because decisions look intentional, not improvised
That is not overhead. That is asset quality.
A Phased Roadmap from MVP to Scalable Product
The right roadmap is staged. Founders get in trouble when they compress all future infrastructure into the present.
A healthy architecture evolves with the company. It does not front-load complexity before the business has earned it.
Phase one uses speed as the priority
At MVP stage, I recommend a NoOps-leaning approach.
Use managed services. Keep the number of deployables low. Build a modular monolith or a very small set of services if there is a clear reason for separation. Focus on product learning, release speed, and clean code boundaries.
At this stage, your architecture should answer one question: can the company learn quickly without creating obvious rewrite risk?
If the answer is yes, you’re doing enough.
Phase two introduces separation where the business demands it
Once the product starts showing traction, your bottlenecks become more concrete.
You may notice that background jobs need different scaling than the API. You may need stronger isolation around auth, tenant-sensitive logic, or a noisy workflow that shouldn’t affect the rest of the system.
That is when service extraction starts to make sense.
Not because microservices are fashionable. Because the product now has domains with different operational realities.
Phase three adopts managed Kubernetes deliberately
When the platform needs repeatable orchestration, stronger workload isolation, and a standardized deployment model, move to a managed Kubernetes platform such as EKS, GKE, or AKS.
The key word is managed.
Founders should not volunteer to build low-level infrastructure competence too early unless the company has a strong platform reason. Managed Kubernetes lets the team gain orchestration benefits without taking on every piece of control plane complexity.
At this stage, keep the design disciplined:
Few services, not many
Strong CI/CD standards
Observability before expansion
Cost controls from the first production cluster
Security baseline in place before enterprise conversations
Phase four hardens for scale and diligence
As the product matures, add the patterns that support operational depth.
That may include service mesh capabilities, stronger runtime security monitoring, more granular autoscaling policies, stricter tenant isolation, and platform controls that support larger engineering teams.
The mistake here is overbuilding. Add complexity only when it reduces a current risk or removes a current bottleneck.
The architecture should be one step ahead of the business, not five steps ahead.
The founder decision framework
Use this simple decision lens:
If your company needs | Then do this |
|---|---|
Fast market validation | Keep infrastructure simple and managed |
Cleaner domain separation | Extract only the services with obvious business boundaries |
Operational consistency across workloads | Introduce managed Kubernetes |
Audit readiness and stronger controls | Harden security, CI/CD, visibility, and cost governance |
Larger team autonomy | Add platform patterns that reduce coordination friction |
My advice is direct. Don’t commit to Kubernetes because you admire the architecture. Commit when your business, team, and product complexity justify it.
That’s how microservices on kubernetes become a long-term asset instead of an expensive distraction.
If you’re deciding whether your startup should stay simple, extract services, or move toward Kubernetes with an investor-ready roadmap, Buttercloud helps founders make that call with product architecture, Fractional CTO guidance, MVP engineering, and audit-ready infrastructure strategy.