DevOps Development Services: A Founder's Guide

Your MVP is live. Customers are using it. Investors want updates. Then the ugly part shows up. Releases happen at night because nobody trusts the deployment process, one cloud misconfiguration can knock out production, and every growth milestone raises a new question about reliability, security, and cost.
That’s the point where founders learn a hard truth. Product quality isn’t just your UI, roadmap, or growth curve. It’s also the system that ships code, protects data, recovers from failure, and proves your team can scale without chaos.
Investors increasingly read infrastructure as signal. If your engineering operation depends on heroics, tribal knowledge, and manual fixes, your codebase stops looking like an asset and starts looking like future cleanup. DevOps development services matter because they turn software delivery into a controlled business system. That system protects valuation.
DevOps Beyond Buzzwords Your Startup’s Technical Moat
Most founders hear “DevOps” and think tooling. Jenkins. GitHub Actions. Docker. Kubernetes. That’s the shallow version. However, it is operational discipline wrapped around software delivery so your company can release fast, recover fast, and stay credible under pressure.
That matters because the market already moved. By 2025, over 78% of organizations globally have implemented DevOps practices, and Fortune 500 companies are at approximately 90% adoption according to this DevOps adoption analysis for 2025. The same source notes that elite performers achieve 46 times more frequent code deployments and 96 times faster recovery from failures. Founders should read those numbers as a valuation signal, not a technical curiosity.
If your team can ship quickly and recover cleanly, you can test pricing, onboarding, integrations, and retention ideas without turning every release into an outage risk. If you can’t, your roadmap slows down exactly when you need conviction and momentum.
What investors actually see
A VC or technical diligence partner doesn’t care that your team “moves fast” if that speed depends on one exhausted engineer with production access. They care whether your startup can produce:
Repeatable releases that don’t rely on manual steps
Clear ownership for incidents, monitoring, and rollback
Audit trails that show who changed what and when
Infrastructure discipline that survives hiring, growth, and turnover
Practical rule: If your startup can’t deploy calmly during business hours, you don’t have a mature product operation yet.
For teams that want a practical companion on the development side, this guide for high-performing dev teams is worth reading because it connects continuous integration habits to the delivery reliability founders need.
DevOps is not support work sitting beside the business. It is part of the business. Done well, it becomes a technical moat because competitors can copy features faster than they can copy execution discipline.
Decoding DevOps Services for Founders
Founders don’t need a dictionary definition. They need to know what they’re buying.
DevOps development services are the operating system for how your company builds, tests, secures, deploys, monitors, and recovers software. You’re not paying for “ops help.” You’re paying for a delivery machine that lowers execution risk.
A lot of early-stage founders make the same mistake. They hire one DevOps engineer and expect that person to solve release automation, cloud governance, monitoring, database reliability, incident response, security controls, and cost management. That’s too much for one hire unless the scope is tiny and the founder is comfortable with key-person risk.
A service model is different. It combines process, tooling, standards, and accountability. It also removes the usual startup pattern where developers throw code over a wall and somebody else cleans up production later.
What the service changes in practice
Here’s the business translation of what a mature DevOps partner does:
Function | What it means for a founder |
|---|---|
CI/CD automation | Releases stop depending on manual steps and memory |
Infrastructure as code | Your environment becomes documented, versioned, and repeatable |
Monitoring and alerting | Problems get detected early instead of through customer complaints |
Secrets and access control | Fewer security shortcuts, cleaner compliance posture |
Backup and recovery planning | Incidents become survivable instead of existential |
That’s why I prefer founders to think in outcomes, not job titles.
Engineer versus service
Hiring an individual can work, but founders should understand the tradeoff.
One engineer gives you capacity. That can be useful if your architecture is already stable and your team knows what to build.
A service gives you a system. That matters more when you need operating standards, not just another pair of hands.
A partner gives you judgment. This is the scarce part. Tools are easy to buy. Architectural discipline isn’t.
Tooling without operating discipline gives startups a polished mess.
The right DevOps engagement aligns engineering with business goals. That means fewer surprise outages before investor demos, cleaner release cycles before enterprise pilots, and less wasted time on infrastructure guesswork when the team should be shipping product.
Choosing Your DevOps Service Model
A founder usually feels the service model decision when something breaks under pressure. A release slips before a customer demo. Production goes down at night. An investor asks who controls infrastructure, access, and deployments, and the answer lives in one engineer’s head. That is not an operations problem. It is a company risk problem.
Your service model determines whether DevOps becomes a transferable asset or a fragile dependency. Choose based on risk, accountability, and how quickly you need an audit-ready operating system. Cost matters, but bad model fit is more expensive than a higher monthly bill.
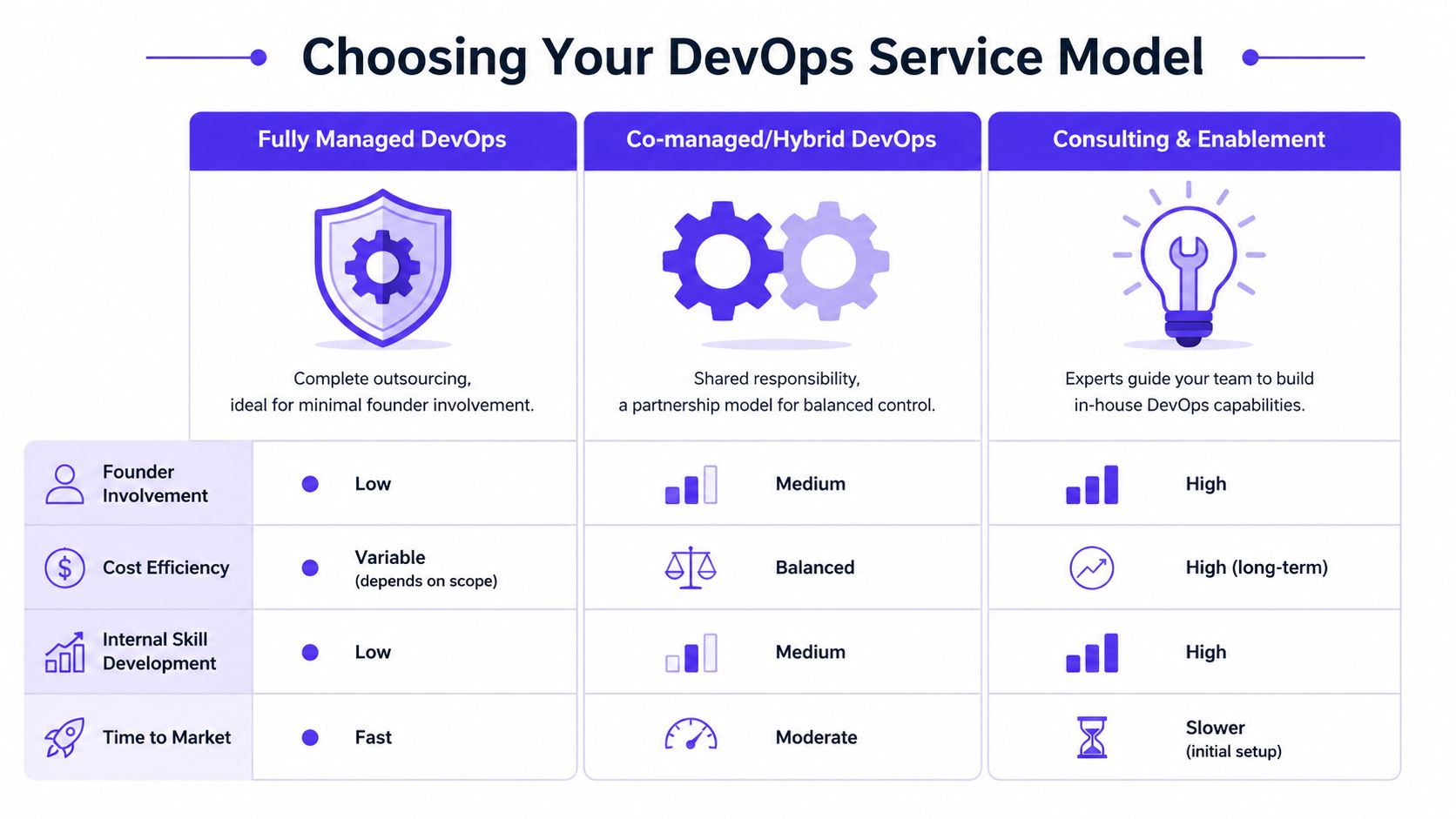
Fully managed DevOps
Fully managed makes sense when the company needs stable delivery now and has no internal operator who should own cloud infrastructure. The provider handles the operational layer, usually including pipelines, deployments, monitoring, incident coordination, and environment maintenance.
This model fits:
Lean founding teams that need to stay on product and go-to-market
Non-technical founders who need clear technical accountability
Teams with short runway that cannot afford infrastructure mistakes
The tradeoff is control. If the provider does not document decisions, codify infrastructure, and expose standards, you get convenience today and diligence problems later. Ask a simple question. If you switch vendors in six months, what exactly transfers cleanly?
Co-managed or hybrid DevOps
For many startups, this is the right answer.
Your team keeps ownership of the product and parts of delivery. The partner adds operating discipline, architecture standards, and release governance. That structure improves execution without turning your platform into a black box. It also gives investors a better story: the company has external expertise, internal visibility, and a system that can survive staff turnover.
Use this model if you have:
developers who can ship product but should not invent ops standards from scratch
growing release pressure across environments and teams
a founder or technical lead who wants oversight without becoming the incident manager
Co-managed usually gives startups the best balance of speed, control, and institutional knowledge.
A practical example is a startup-focused partner such as Buttercloud. In this model, managed infrastructure and CI/CD can sit beside founder-level technical oversight rather than replacing it. If you want a reference point for what mature pipeline ownership should include, review this guide to CI/CD in DevOps.
Consulting and enablement
Consulting works when you are deliberately building an internal platform capability. The consultants design the standards, implement the foundation, and train your team to run it without long-term external ownership.
Choose this model when:
Your engineers are strong enough to operate the system after handoff
You want infrastructure ownership to stay in-house
You are willing to spend more time upfront to reduce outside dependency later
Do not choose consulting if production is already fragile and nobody internally can own the result. Advice is useless without execution capacity.
A simple decision matrix
Situation | Best-fit model | Why |
|---|---|---|
MVP needs reliable releases now | Fully managed | Immediate operational coverage matters more than internal capability |
Product has traction and a small engineering team | Co-managed | You need shared ownership, release discipline, and visibility |
Strong team preparing to internalize ops | Consulting and enablement | The goal is to build a repeatable in-house capability |
The founder test
Use these questions to pressure-test your choice:
Who responds first when production fails outside business hours?
What part of the release process breaks if one senior engineer leaves?
Can you explain infrastructure ownership, access control, and deployment governance in a VC diligence meeting without improvising?
If the answers are weak, the cheapest option is the wrong option. Buy the model that reduces key-person risk, creates operating evidence, and turns infrastructure from hidden liability into an investable asset.
Audit-Ready Deliverables of DevOps Services
A founder should never sign a DevOps contract that sells “support” without naming artifacts, standards, and accountability. You need deliverables, not vibes.
The first thing to demand is a working release system. That means CI/CD pipelines that build, test, and deploy code consistently. It also means those pipelines are optimized, not just present. According to this CI/CD cloud cost optimization playbook, implementing pipeline optimizations like caching can reduce pipeline runtime by 40-60%, which translates into proportional compute cost savings. For a startup, that’s not a minor technical tweak. It’s cost-efficient velocity.

If you want a deeper operational breakdown of release automation, Buttercloud’s article on CI/CD in DevOps is a useful reference for what the pipeline should accomplish.
The non-negotiable deliverables
A real DevOps engagement should produce a clear operating stack. At minimum, ask for these items.
CI/CD pipeline architecture with build, test, deploy, rollback, and approval logic
Infrastructure as code in Terraform, Pulumi, or an equivalent system, stored in version control
Environment strategy for dev, staging, and production
Monitoring and alerting using tools such as Datadog, Grafana, Prometheus, New Relic, or CloudWatch
Centralized logs so incident review doesn’t depend on SSH sessions and guesswork
Secret management using a proper vault or cloud-native secret service
Backup and disaster recovery procedures that are documented and tested
Security scanning in the delivery pipeline for dependencies, images, and code
What founders should ask to see
Don’t accept “we have this covered.” Ask for evidence.
Pipeline proof
You should be able to watch a commit move through build, test, and deployment steps. If the provider can’t demo that flow, they don’t have a mature delivery practice.
Infrastructure repos
Ask where infrastructure definitions live, who can approve changes, and how production drift is detected.
Operational dashboards
A healthy service includes live dashboards for latency, errors, resource usage, deployment status, and alert history.
Founder lens: Every DevOps deliverable should answer one of three questions. How do we ship? How do we detect failure? How do we recover?
SLAs are where accountability lives
Service Level Agreements matter because they turn promises into operating commitments. Founders should pay attention to:
SLA area | What it tells you |
|---|---|
Uptime target | How seriously the provider treats service continuity |
Incident response window | How quickly someone engages when production is down |
Support coverage | Whether help exists only during office hours or when you actually need it |
Escalation path | Who gets involved if the first line can’t solve it |
Recovery expectations | Whether rollback and restoration are planned or improvised |
If the provider can’t state incident response expectations cleanly, you’re not buying reliability. You’re buying optimism.
The ROI Framework for Startup DevOps
Founders often ask the wrong question. They ask, “How much will DevOps cost?” The better question is, “What does operational immaturity cost us if we delay?”
That’s the right lens because infrastructure debt rarely shows up as a clean line item. It shows up as delayed releases, investor concern, expensive refactors, team distraction, and product instability at exactly the wrong moment.
Where the return actually comes from
The biggest return usually comes from four places.
Value driver | Business effect |
|---|---|
Faster release cycles | You test product and growth assumptions sooner |
Lower interruption load | Engineers spend more time building features |
Cleaner diligence posture | Investors see a durable technical asset |
Better cost governance | Cloud usage becomes controlled instead of reactive |
The Infrastructure as Code decision captures the tradeoff well. Startups face a real dilemma. Implementing IaC early adds upfront overhead, but it prevents technical debt that surfaces during investor audits, and the ROI turns positive when you factor in the cost of refactoring during Series A due diligence, as explained in this founder-relevant take on the future of DevOps and IaC governance.
That’s why I tell founders to stop treating IaC as optional polish. It’s governance. Governance affects diligence. Diligence affects fundraising advantage.
A blunt risk matrix
Not every DevOps investment is smart. Some are premature. Some are overbuilt. Some are handed to the wrong vendor.
Over-engineering before product-market fit You don’t need a giant platform team for a product nobody wants yet. You do need basic release safety, visibility, and reproducibility.
Vendor lock-in through opacity If a partner won’t document systems, store infrastructure in your repositories, or train your team, they are building dependence.
Cheap implementation with hidden cleanup A low-cost provider that hardcodes environments, skips observability, and ignores access discipline creates a larger bill later.
Engineering distraction If your product engineers spend too much time babysitting cloud infrastructure, your roadmap slows. Therefore, founders should look for ways to reclaim engineering focus so product work doesn’t get swallowed by operational drag.
Investors forgive a lean team. They don’t forgive a fragile system that obviously won’t survive scale.
A practical board-level test
A DevOps investment is justified when at least one of these is true:
Releases are slow because nobody trusts production
Customer-facing incidents are stealing engineering time
Fundraising or enterprise sales requires stronger technical diligence answers
Cloud costs keep rising without clear ownership or policy
If none of those are true, keep the system lightweight. If two or more are true, you’re already paying the penalty for not fixing it.
Integrating Security and Compliance into Your Build
A founder walks into a diligence call feeling prepared. The product works, revenue is growing, and the roadmap is clear. Then the investor asks simple questions. Who can access production? How are secrets rotated? Can you show a change log for infrastructure? If your team cannot answer in minutes, your technical asset looks risky, no matter how good the demo is.
Security and compliance belong inside the build process because that is where investor confidence is won or lost. Late-stage reviews create delay, force rework, and expose weak operating discipline. DevSecOps matters because it turns security from a periodic fire drill into a repeatable part of delivery.
Many teams miss the point. They buy scanners and keep the same habits. Booz Allen’s perspective on the DevSecOps technology trap makes the right argument. Tools do not fix a team that treats security as someone else’s job.
What that means for a founder
You are not buying a stack of security products. You are setting operating rules that make the company easier to fund, easier to sell, and harder to break.
That means:
Developers handle security findings during delivery, while context is still fresh
Secrets live in managed systems, not in chat threads, docs, or local machines
Infrastructure changes are logged and reviewable, so audits rely on records instead of memory
Release approvals include security checks, before code reaches customers
This discipline has direct commercial value. Enterprise buyers ask for it in procurement. Investors test for it in technical diligence. Regulated startups feel the pressure even earlier. If you operate in fintech or adjacent markets, this overview of fintech compliance requirements for startup teams is a useful reference point.
Put controls where code changes
The right place for security is inside the path from commit to production. That includes dependency checks, infrastructure policy checks, access control, secret management, and reviewable deployment approvals.
A useful outside primer is this comprehensive guide for SSDLC, which connects secure development practice to daily engineering decisions. The point is simple. Security should produce evidence. Evidence is what passes diligence.
Security should increase trust in releases and reduce diligence risk.
What to insist on
Ask any DevOps partner these questions:
Question | Why it matters |
|---|---|
How are secrets stored and rotated? | This shows whether basic access discipline exists |
Where do security scans run in the pipeline? | This shows whether security is continuous |
How are access privileges reviewed? | This shows whether production access is controlled and limited |
What audit trail exists for infrastructure changes? | This determines whether you can answer diligence and compliance questions with proof |
You do not need to become a security engineer. You do need a partner who can build repeatable controls, document them clearly, and train your team to operate them without drama.
A Founder’s Roadmap to Implementing DevOps
You are three weeks from a fundraise. An investor asks a simple question: how does code get to production, who can change infrastructure, and what proof do you have that releases are controlled? If your answer depends on one engineer’s memory, your company carries diligence risk that shows up in valuation.
The right roadmap is phased. Founders lose money in two predictable ways. They postpone DevOps until outages, cloud waste, and release delays start hurting growth, or they overbuild an enterprise stack long before the business needs it.
Use a staged rollout. Establish control first. Then add the systems that improve reliability, cost discipline, and investor confidence.
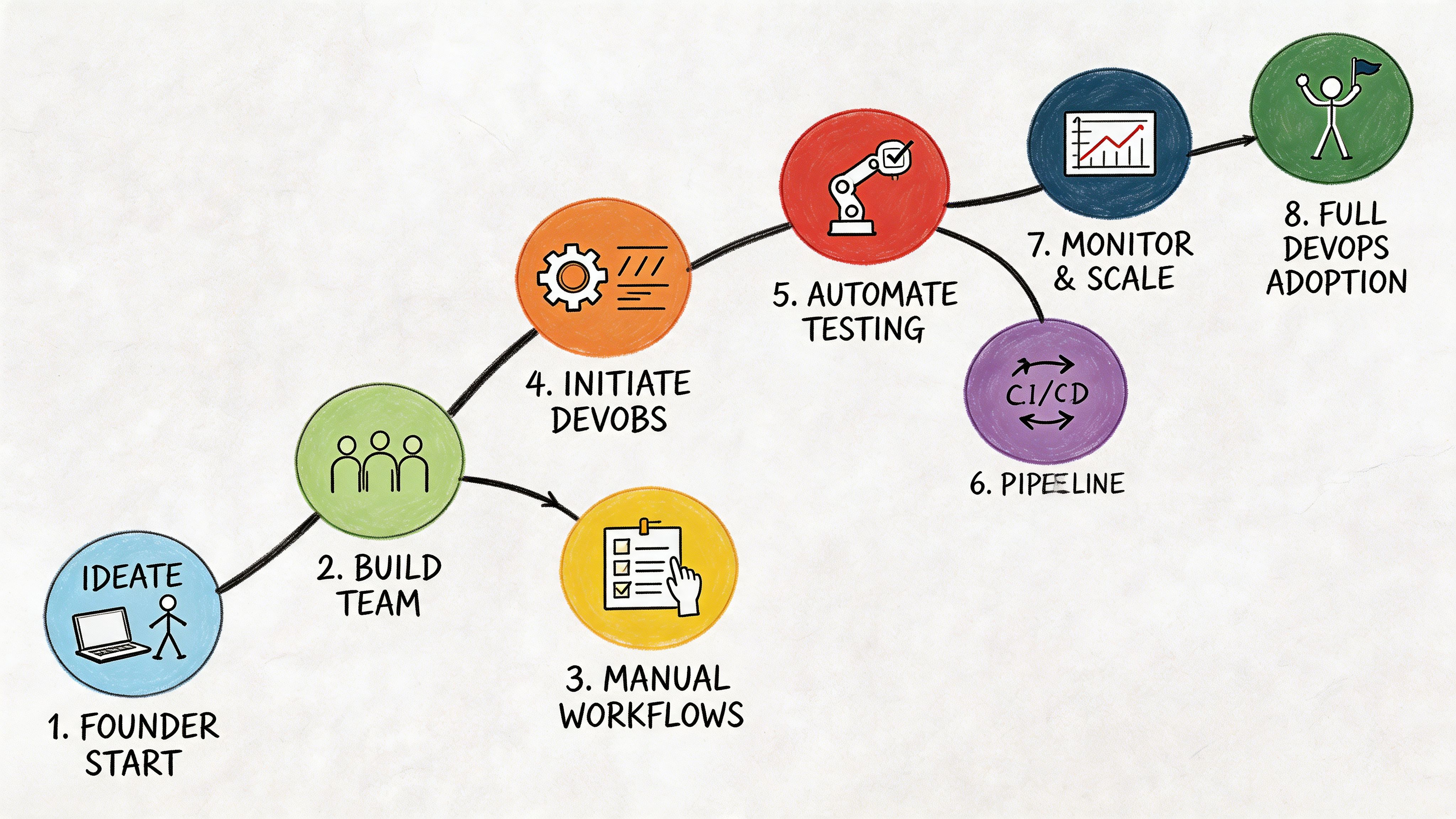
Step 1 assess operational fragility
Start with an honest inventory. Ask questions that expose hidden dependency and process debt.
Release risk. Are deployments manual, undocumented, or dependent on one person?
Environment drift. Does staging meaningfully match production?
Incident visibility. Do you learn about failures from customers?
Security basics. Are secrets, permissions, and backups handled consistently?
Cost discipline. Can anyone explain why the cloud bill changed last month?
If the answers are vague, stop shopping for tools. Find the failure points first.
Step 2 choose the smallest high-leverage fix
Most startups should start with CI/CD, environment standardization, and monitoring. Those three changes reduce operational chaos without dragging the team into platform engineering theater.
A fintech MVP heading into investor demos does not need an elaborate internal platform. It needs predictable releases, clean rollback paths, and a production environment the team can explain. A SaaS company approaching real usage growth needs the same foundation, plus better performance signals and database visibility.
Start where failure is expensive and repetition is high. Automation delivers the most value there.
Step 3 run vendor selection like diligence
Do not let a provider hide behind jargon or a tool list. Ask questions that reveal whether they can build an asset your company can defend under scrutiny.
Questions that expose fluff
How do you store infrastructure definitions?
What happens during a failed deployment?
How do you handle secret management?
What monitoring stack do you recommend and why?
How do you transfer knowledge to our internal team?
What would you not implement yet at our stage?
That last question matters. A good partner protects focus. Restraint is part of good architecture.
Step 4 implement in phases
Phase one stabilizes releases
Set up CI/CD, standardize environments, and define access controls. Tools might include GitHub Actions, GitLab CI, CircleCI, Terraform, Datadog, or Prometheus, depending on the team and stack.
Expected outcome: lower release stress, cleaner handoffs, and fewer late-night surprises.
Phase two hardens production
Add alerting, centralized logs, backup procedures, rollback strategy, and security scanning. At this point, your operating model starts producing evidence instead of relying on verbal assurances.
Expected outcome: incidents become diagnosable and survivable.
Phase three governs growth
Introduce stronger cloud policies, deeper observability, cost dashboards, and data-layer optimization. This is also the stage where database reliability starts shaping gross margin and delivery speed.
Implementing Database Reliability Engineering within a managed DevOps service can improve infrastructure efficiency through automated resource optimization, according to this DRE and data management analysis. For a scaling startup, that means infrastructure costs become easier to predict instead of drifting upward through guesswork.
Step 5 define ownership before scale forces it
Roadmaps fail when ownership is vague. Even with an external partner, assign internal owners for:
Release approvals
Incident communication
Cloud spend review
Security exception decisions
Documentation maintenance
Without clear ownership, every process degrades under pressure.
Step 6 create a review rhythm
Review DevOps operations on a schedule, not only after something breaks. A monthly review is enough in the early stage. Focus on release friction, avoidable failures, cost anomalies, and upcoming diligence or compliance demands.
A useful review format looks like this:
Review area | What to check |
|---|---|
Release health | Failed builds, rollback frequency, deployment friction |
Reliability | Alert noise, unresolved incidents, recurring weak points |
Cost control | Unexpected spend changes, underused resources |
Security posture | Open findings, access reviews, secrets hygiene |
Step 7 avoid the two common founder errors
The first error is waiting until fundraising to clean up infrastructure. Then the team is rushing through remediation while investors are already asking questions.
The second error is outsourcing everything and learning nothing. You need a system your company can operate and explain. A black box lowers control and raises key-person risk.
Step 8 make investability the standard
The endpoint is not “we have DevOps now.” The endpoint is a delivery system that helps your startup ship product, survive incidents, answer diligence questions with evidence, and scale without operational panic.
That is what investors want to see. It is also what strong engineering hires look for when they decide whether your company is built to last.
Your Next Step Toward an Investable Tech Asset
A founder’s infrastructure decision is never just an engineering choice. It shapes release speed, incident risk, cloud efficiency, compliance posture, and how credible the company looks under technical scrutiny.
That’s why I advise founders to stop viewing DevOps development services as a support function. They are part of capital formation. They help convert code into an investable asset by making the software delivery system repeatable, observable, secure, and defensible.
If your team still deploys manually, relies on undocumented production knowledge, or treats security as a final checkpoint, you are carrying hidden valuation risk. Fix that before the next growth milestone forces you to fix it under pressure.
The right move is usually not a giant transformation. It’s a disciplined one. Start with release automation. Add infrastructure as code. Build monitoring and security into the workflow. Demand clear deliverables and real accountability from any partner you hire.
Founders who do this early gain more than smoother deployments. They gain an advantage. They can move faster without looking reckless. They can raise with fewer technical objections. They can hire better engineers because the system those engineers inherit works.
That’s the standard. Build for investability, not just launch.
If you’re building toward an investor-ready MVP or preparing your product for scale, Buttercloud helps founders turn fragile codebases into production-grade technical assets through product engineering, fractional CTO leadership, and startup-focused DevOps discipline.