Master MVP Project Management: A Step-by-Step Guide

You’re likely in one of two situations right now.
You either have a product idea and too many opinions from advisors, freelancers, and investors. Or you already shipped something that technically works, but you can feel the architecture straining under even modest traction.
That’s where mvp project management usually breaks down. Founders treat the MVP as a speed exercise. It isn’t. It’s a capital allocation exercise, a product validation exercise, and a technical governance exercise at the same time.
A weak MVP gives you noisy feedback, brittle code, and false confidence. A strong MVP gives you usable evidence, a clean path to scale, and a codebase that survives investor scrutiny. The difference isn’t luck. It’s how you scope, measure, sequence, and govern the build from day one.
Why Production-Grade MVPs Matter
Most founders make the same mistake. They ask, “What’s the fastest thing we can launch?” when they should ask, “What’s the smallest thing we can launch without poisoning the next stage of the company?”
That distinction matters.
An MVP is common for a reason. Approximately 72% of startups adopt an MVP approach, and that approach can slash development costs by up to 60% while accelerating time-to-market by about 35%, according to SDH Global’s review of MVP startup survival statistics. But those benefits only matter if the product is viable in production, not just demo-friendly.
Minimal doesn’t mean disposable
A prototype can be rough. An MVP cannot.
If users hit broken flows, missing safeguards, or obvious instability, you’re not validating demand. You’re validating that people dislike broken software. That feedback is useless.
A production-grade MVP should do four things well:
Solve one real problem end-to-end
Generate measurable user behavior
Support change without a rewrite
Avoid obvious security and data handling mistakes
That last point gets ignored too often. Founders postpone architecture, testing discipline, and compliance thinking because they assume they can “clean it up later.” Usually, later arrives when a customer asks hard questions, a due diligence process starts, or the team tries to add a second major workflow and discovers the foundations are weak.
Practical rule: If your MVP can’t survive three rounds of iteration without structural rework, it’s not an MVP. It’s an expensive mockup.
Build the asset, not the screenshot
Serious founders should treat the MVP as the first investable version of the company’s technical asset. That doesn’t mean overengineering. It means engineering for controlled growth.
A useful reference point is the broader new product development process, especially if you’re trying to connect early product validation with longer-term roadmap discipline. MVPs work best when they sit inside a structured product process, not outside it.
A production-grade standard usually includes:
Clean system boundaries so your core logic isn’t scattered across the codebase
Basic test coverage around core user flows
Deployment discipline so releases are repeatable
Logging and monitoring so the team can diagnose failures
Security hygiene around auth, permissions, and data storage
If you need a founder-level perspective on what that build path looks like in practice, this guide on how to build an MVP is worth reviewing before you commit budget.
The right question to ask
Don’t ask whether your MVP is “lean.” Ask whether it’s credible.
Credible to users. Credible to engineers. Credible to investors. Credible to the next hire who inherits it.
That’s the bar.
Defining Clear Outcomes and Success Metrics
Founders love shipping. Investors love progress. Neither one cares about motion if the product isn’t producing signal.
A surprising number of teams still launch with vague goals like “get traction” or “see what users do.” That’s lazy product management. If you don’t define success before release, your team will cherry-pick whatever number looks flattering after release.
Research summarized by the International Association of Project Managers notes that 37% of projects fail due to lack of specific goals, and it also emphasizes defining hypotheses and KPI thresholds before shipping in a build-measure-learn loop through its MVP project management guidance.
Start with a business hypothesis
Every MVP needs a blunt, testable statement.
Not “users need a better platform.”
Not “AI will improve workflow.”
Not “small businesses want automation.”
Write the actual bet.
Examples:
A sales team will complete onboarding if setup takes less effort than their current spreadsheet process.
Busy parents will reorder from a mobile flow if checkout removes repeat entry friction.
A B2B operations team will pay for workflow visibility if the product reduces manual status chasing.
That hypothesis should point directly to a behavior you can measure.
Use outcome metrics, not vanity metrics
For MVP project management, the most useful metrics are the ones tied to user value. The verified benchmark here is clear: activation, retention, conversion, engagement, and churn are the core set to track. High-performing MVPs often target Day 30 retention above 40% and conversion rates of 5 to 10%, according to monday.com’s MVP project management guide.
Here’s how to think about each one:
Metric | What it answers | Why founders should care |
|---|---|---|
Activation | Did the user complete the core action? | This tells you whether the product delivers initial value. |
Retention | Did the user come back? | This separates curiosity from actual utility. |
Conversion | Did the user sign up or pay? | This tests commitment, not just interest. |
Engagement | How often do users use the core feature? | This shows whether your main workflow matters in real life. |
Churn | Who left and stayed gone? | This reveals whether you’re solving a recurring problem. |
Downloads, page views, and social mentions can be useful context. They should never drive product decisions on their own.
Don’t celebrate reach when the product fails at activation. Don’t celebrate signups when retention is weak. Early metrics have a sequence, and founders need to respect it.
Define thresholds before writing code
The team should know, in advance, what counts as a pass, a warning, and a failure.
A simple format works well:
Hypothesis: Users will complete the primary workflow without support.
Primary KPI: Activation
Threshold: Team-defined target for successful completion
Secondary KPI: Retention or conversion
Qualitative check: User interview confirms the workflow solved the intended problem
That forces discipline. It also helps when the product gets mixed feedback. Instead of debating opinions, you compare results against pre-agreed thresholds.
Build a measurement plan into the sprint plan
Many teams sabotage themselves at this stage. They define KPIs in a slide deck, then forget to instrument the product.
Every MVP sprint should include analytics and feedback work, not just feature work.
A practical setup looks like this:
Event tracking: Use tools like Mixpanel, PostHog, Amplitude, or GA4 to track core actions
Session insight: Use FullStory, Hotjar, or comparable tools to observe drop-off patterns
Survey capture: Add short in-product prompts after the core workflow
Interview loop: Schedule founder-led calls with a small set of users after launch
A usable outcome statement
Founders need one sentence that aligns product, engineering, and commercial priorities.
Use this structure:
We believe [specific user segment] will [complete meaningful action] because [value hypothesis]. We’ll know we’re right when [primary KPI threshold] and [secondary KPI or qualitative confirmation].
Example:
We believe first-line managers will complete weekly team check-ins inside the product because it reduces manual coordination. We’ll know we’re right when activation reaches the agreed threshold, repeat usage remains healthy, and interviews confirm the product replaced an existing workaround.
That statement is more useful than ten pages of strategy language.
Pair numbers with direct user feedback
Quantitative data tells you what happened. It rarely tells you why.
A user might activate once and never return. That could mean the workflow is weak, the positioning was wrong, onboarding was confusing, or the problem wasn’t painful enough. You won’t learn that from a dashboard alone.
Use short interviews and in-product survey prompts to answer questions like:
What were you trying to accomplish?
Where did the flow feel unclear?
What almost stopped you from completing the task?
Would you use this again for the same job?
The dashboard should be boring
That’s a compliment.
A good MVP dashboard isn’t packed with decorative charts. It highlights a few decisions:
Are users reaching value?
Are they coming back?
Are they paying or committing?
Are they dropping at the same place?
Are we learning enough to continue, refine, or pivot?
If your dashboard can’t answer those questions in a few minutes, it’s built for status theater, not decision-making.
Prioritizing Features and Building Sprint Plans
Once outcomes are clear, the next mistake appears fast. Founders turn the MVP backlog into a wishlist.
That’s how scope balloons, timelines slip, and engineers start making rushed compromises to fit impossible asks. Good mvp project management is mostly the discipline of saying no early enough that the team can still build well.
The operational case for that discipline is strong. Agile-led MVP projects achieve a 64 to 67% success rate versus 49% for traditional methods, and projects with defined scope boundaries and risk management push success above 79%, according to Ravetree’s project management statistics roundup.
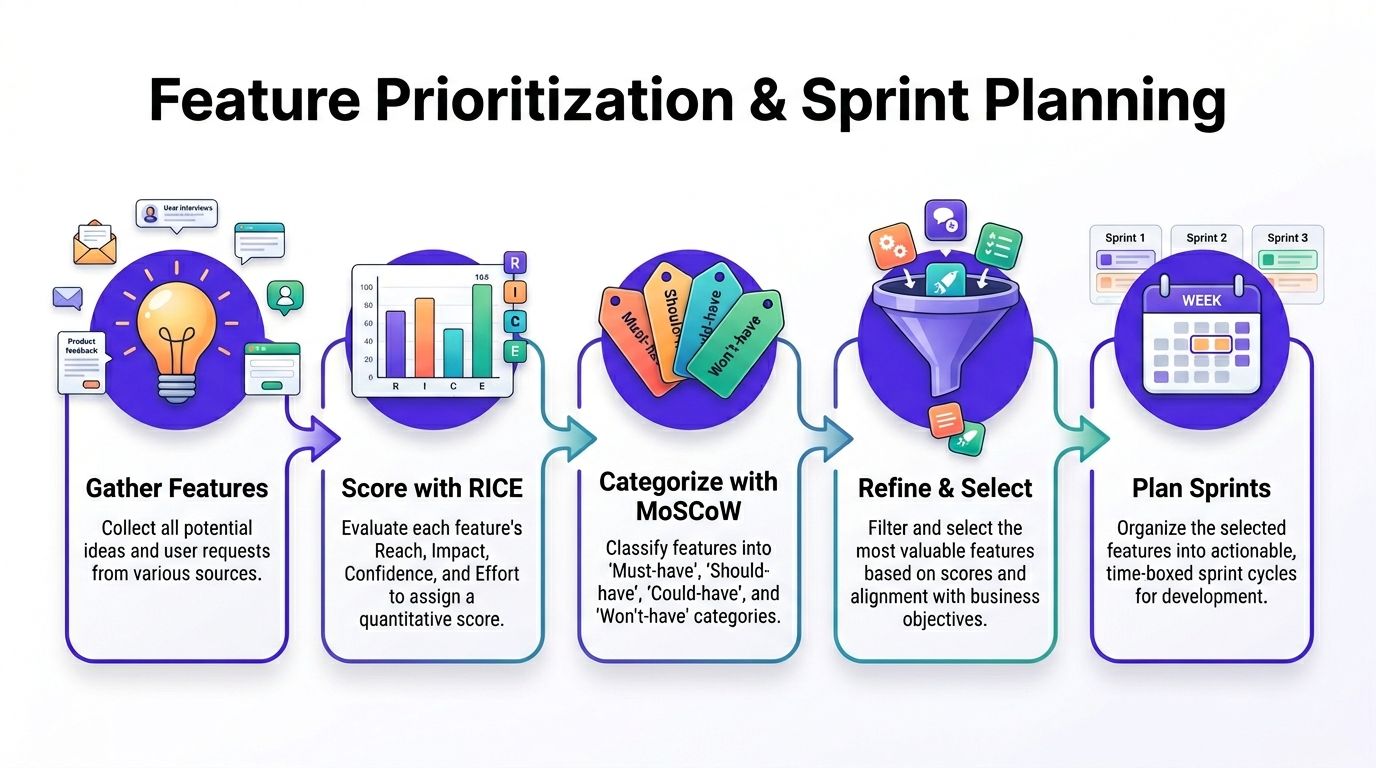
Use a layered prioritization method
No single framework is enough on its own. I recommend combining three.
RICE for commercial weight
Use Reach, Impact, Confidence, and Effort to compare candidate features. This is useful when you have several plausible options competing for the same sprint.
Ask:
How many users will this affect?
Does it improve the main KPI or just decorate the experience?
How confident are we that it matters?
What’s the engineering cost?
RICE is especially useful for cutting founder pet features that sound smart but don’t move the core hypothesis.
MoSCoW for scope control
Then classify items as:
Must-have
Should-have
Could-have
Won’t-have for this release
This step matters because founders often confuse “important eventually” with “required now.” A feature can be valuable and still belong outside the MVP.
User story mapping for flow logic
Finally, map the user journey from first touch to core outcome.
That exposes hidden gaps. Teams often prioritize features individually and miss the fact that the end-to-end flow still breaks in the middle. Story mapping forces continuity.
What belongs in sprint zero
Sprint zero shouldn’t become a black hole of planning. It has one purpose. Remove ambiguity before feature velocity begins.
A strong sprint zero usually includes:
Product decisions: Confirm the core user journey, acceptance criteria, and KPI instrumentation plan
Architecture choices: Define app structure, data model boundaries, and external integrations
Delivery setup: Configure repo standards, CI/CD, environments, issue tracking, and release process
Risk review: Identify security, compliance, and dependency risks that can disrupt later sprints
This work doesn’t slow the project. It prevents expensive confusion.
Operational advice: If the team can’t describe the MVP in one user journey and one system diagram, you’re not ready to sprint.
A practical sprint plan
Most founders don’t need a complex agile ritual stack. They need a simple sprint machine that stays aligned with the hypothesis.
A typical two-week sprint should include a mix of build, verify, and stabilize tasks.
Sprint element | What to include |
|---|---|
Primary build work | Only features tied directly to the current KPI hypothesis |
Architecture task | One bounded technical item that protects future change |
Instrumentation | Events, funnel tracking, and basic reporting |
Quality work | Test coverage for the critical path |
Review checkpoint | Demo against the acceptance criteria, not against opinion |
That structure prevents a common failure mode where the team builds visible product surface but neglects observability and quality.
Definition of done must be strict
Founders often accept “code complete” as done. That’s not done. That’s the beginning of downstream problems.
A feature should only be considered done when:
the user can complete the intended task,
analytics events fire correctly,
edge cases for the main path are covered,
the feature passes review,
and the release can be deployed predictably.
Without that discipline, your velocity report is fiction.
Protect capacity for technical work
You do not need a separate “technical debt phase” at the end of the MVP. That usually means the team already lost control.
Instead, reserve visible sprint capacity for structural work throughout the build. That can include auth hardening, test improvements, refactoring a fragile module, or cleaning up an integration boundary.
Founders resist this because it looks like non-feature work. Then they pay for it later in delays, incidents, and rebuilds.
Stakeholder management needs hard boundaries
If you have investors, advisors, pilot customers, and internal stakeholders all feeding requests into the backlog, somebody has to control the gate.
Use a simple decision filter:
Does this item improve the current hypothesis?
Is it required for the core user journey to function?
Does delay create meaningful risk?
Can it wait one release without damaging the business?
If the answer is no to all four, cut it.
Feature prioritization isn’t diplomacy. It’s governance.
Structuring the Team and Embedding DevOps & Security
A founder can’t run MVP delivery with a pile of disconnected specialists and hope the product comes out coherent. You need a tight team with clear ownership, fast communication, and technical standards that are visible from the first sprint.
The build isn’t just features. It’s delivery capability.
The smallest team that usually works
For most MVP efforts, the right team is cross-functional and compact.
A practical structure often includes:
Product lead who owns priorities, user decisions, and acceptance criteria
Technical lead or fractional CTO who owns architecture, delivery risk, and technical tradeoffs
Engineer or small engineering pod who builds the product across frontend and backend boundaries
DevOps ownership for environments, deployment, observability, and release confidence
QA or compliance-minded reviewer who checks critical paths, regressions, and obvious security issues
One person can cover multiple roles in a small team. What matters is that the responsibilities are explicit.
If you’re assembling the wrong shape of team, this breakdown on choosing a team of developers is a useful reference point.
Don’t bolt on DevOps later
Founders often assume DevOps starts when scale starts. Wrong.
You need delivery discipline immediately, because even a simple MVP will produce releases, bugs, environment issues, and rollback decisions. If the team can’t ship safely and repeatedly, every change becomes stressful.
A sensible early setup includes:
Source control discipline with protected branches and review requirements
CI/CD pipelines using tools such as GitHub Actions, GitLab CI, or comparable systems
Automated tests for the most important paths
Logging and error tracking through tools like Sentry, Datadog, or equivalent
Basic environment separation so development work doesn’t contaminate production
Security belongs inside sprint work
Security isn’t a milestone. It’s a practice.
That means every sprint should account for the basics:
Area | What the team should do |
|---|---|
Authentication | Use proven auth flows and avoid homegrown shortcuts |
Authorization | Check permissions at the server and application layers |
Dependencies | Review packages and libraries for known issues |
Secrets management | Keep credentials out of code and shared docs |
Data handling | Be explicit about what user data is stored and why |
This becomes even more important if you’re selling into regulated markets or dealing with sensitive user information. Founders who postpone this work usually end up reworking core infrastructure under pressure.
Teams that embed code review, deployment checks, and security thinking into the weekly rhythm move faster than teams that treat them as cleanup.
Pick infrastructure that matches your stage
Early-stage teams shouldn’t chase infrastructure complexity to look advanced.
Use managed services where they reduce operational burden. Use self-managed infrastructure only where control is required. The goal is not to prove technical ambition. The goal is to preserve focus and reduce failure points.
A mature MVP team also documents a few operational basics from day one:
release ownership,
incident escalation,
rollback expectations,
and who approves changes that affect risk.
That level of structure isn’t corporate overhead. It’s what keeps a small team from breaking itself with avoidable mistakes.
Balancing Cost Time Tradeoffs and Managing Technical Debt
Every MVP includes tradeoffs. The problem isn’t taking shortcuts. The problem is taking shortcuts blindly.
Founders usually frame the decision badly. They think the choice is between moving fast and moving slowly. The choice is between controlled debt and uncontrolled debt.

The gap in most MVP advice is obvious. Existing guides routinely ignore the hidden cost of technical debt, while founder regret often spikes after launch when legacy code and weak security hardening create investor pushback and expensive refactoring, as discussed in this analysis of the MVP technical debt gap.
Not all debt is equal
Some debt is acceptable. Some debt is reckless.
A practical debt ledger should classify issues into categories like these:
Architecture debt such as duplicated business logic or unclear service boundaries
Testing debt where core paths lack reliable regression checks
Documentation debt when only the original builder knows how the system works
Security debt including weak access controls or sloppy data handling
Operational debt such as manual deployments and poor observability
If a shortcut touches the payment flow, auth model, or core data structure, treat it as high risk. If it affects a non-critical admin view or a temporary internal workflow, you may choose to defer it.
Use a decision filter before accepting debt
When the team proposes a shortcut, ask four questions:
What exactly are we deferring?
What breaks if this remains in place for multiple releases?
How hard will it be to unwind later?
Does this increase investor or customer diligence risk?
Those questions force precision.
A founder should be able to say, “We are accepting this debt intentionally, for this reason, and we will revisit it at this checkpoint.” If you can’t say that, you’re not making a tradeoff. You’re drifting.
The hidden budget problem
Technical debt isn’t just a code quality issue. It changes your budget profile.
Teams with unmanaged debt burn time in places founders don’t immediately see:
Bug fixing starts displacing roadmap work.
New features take longer because old assumptions are brittle.
Onboarding new engineers slows down because system logic is tribal knowledge.
Security and compliance reviews turn into fire drills.
That’s one reason investor conversations often get harder after an MVP launch, not easier. If you’re preparing for funding and want to understand the broader funding environment around early-stage builds, this overview of Best Angel Investors Options For Mvp Development Companies In Uae offers useful context on the ecosystem founders are navigating.
Keep a live debt ledger
Don’t bury debt in engineering memory. Track it openly.
A useful debt ledger includes:
Field | What to capture |
|---|---|
Debt item | Clear description of the compromise |
Category | Architecture, testing, security, docs, or operations |
Reason accepted | Why the team deferred the better solution |
Current impact | What friction or risk it creates now |
Trigger to fix | Event that forces remediation |
Owner | Who is accountable for resolution |
This turns debt into a managed liability instead of a vague future problem.
A good founder doesn’t demand zero technical debt. A good founder demands that every debt item has an owner, a rationale, and a trigger for cleanup.
Schedule refactoring windows before you need them
The right time to plan cleanup is before the system starts resisting change.
Insert bounded refactoring tasks during the MVP lifecycle. Not after a collapse. During normal execution. That keeps complexity from hardening into your default operating model.
Speed matters. Clean architecture matters too. Smart founders stop pretending those goals are enemies.
Preparing Handoff and Scaling Post-MVP
A launched MVP is not a finish line. It’s a transfer point.
The company is about to move from “Can we build and validate this?” to “Can this system support more users, more team members, and more operational pressure without turning chaotic?” If the handoff is weak, the next phase becomes slower than it should be.
Another gap in current MVP guidance is that modern guides often lack structured KPI benchmarks and feedback velocity frameworks. Without them, founders struggle to decide when to scale infrastructure versus pivot product, which creates unvalidated investment risk, as noted in this review of missing MVP validation frameworks.
The handoff pack should be real, not ceremonial
Most handoff documents are too shallow to help and too long to read. Build a handoff pack that another technical lead could use.
That pack should include:
Architecture overview with system boundaries, key services, and dependency map
Environment and deployment notes covering how releases happen and how issues are diagnosed
Core data model summary so new engineers understand what matters
Runbooks for routine operations and failure scenarios
Known risks and debt ledger with explicit priorities
Product KPI definitions so the next team measures the same outcomes the first team validated
This isn’t bureaucracy. It’s continuity.
Decide what scale means before buying scale
Many teams waste money on premature infrastructure because they confuse growth ambition with current operational need.
Founders should define specific triggers for scaling decisions. Not generic statements like “when traffic grows.” Use real operating signals from the product and team.
For example, ask:
Is the current system failing under actual usage?
Is a specific service becoming a bottleneck?
Are reliability issues affecting retention or conversion?
Is engineering speed dropping because the architecture is too tightly coupled?
If the answer is no, don’t overbuild.
Monitoring comes before optimization
You can’t scale what you can’t see.
Before you expand infrastructure, make sure the product has:
Application monitoring for errors and performance
Business dashboards for the core behavioral metrics
Alerting for meaningful failures
Basic cost visibility across your cloud or platform stack
That gives you a baseline. Without a baseline, every scaling move is guesswork.
The right post-MVP question isn’t “How do we scale fast?” It’s “What evidence says this part of the system needs scaling now?”
Prepare for people scale too
Technical handoff is not only about systems. It’s also about people.
A new engineer, internal hire, or outside partner should be able to answer these within the first onboarding cycle:
Question | What should exist |
|---|---|
How does the product make money or create value? | Business context and KPI definitions |
What does the core workflow look like? | User journey documentation and demos |
How is the system deployed and supported? | CI/CD notes, runbooks, and access process |
Where are the sharp edges? | Debt ledger, risk notes, and recent incidents |
That level of clarity shortens onboarding and reduces accidental damage.
Scale the roadmap, not just the servers
Post-MVP scaling usually requires tighter ownership, stronger roadmap discipline, and more explicit service boundaries. It may also require changes in database design, job processing, multi-tenant isolation, or cloud spend controls. But those should follow validated demand, not founder anxiety.
The best handoff enhances efficiency. It gives the next team enough context to move quickly without relearning expensive lessons.
Final Thoughts and Next Steps
Most founders don’t fail at mvp project management because they lack ambition. They fail because they confuse speed with progress.
A strong MVP starts with a sharp hypothesis. It moves through disciplined scope control, measured sprint execution, and a team structure that includes DevOps and security from the start. It stays honest about technical debt. Then it hands off with enough clarity that the company can scale without rebuilding its own foundation.
If you’re building now, take these steps next:
Write the business hypothesis in one sentence
Define success thresholds before development starts
Cut the backlog to one end-to-end user journey
Set delivery and security standards for every sprint
Track technical debt as a managed liability